
目次
本記事のポイント
- データアナリストが直面するSQL記述・デバッグの課題を、ChatGPTがいかに解決し、生産性を向上させるか理解できます。
- ChatGPTを活用したSQL生成の基本から、既存クエリのデバッグ・最適化、テーブル構造からの自動生成まで、実践的なプロンプト例とともに習得できます。
- 複雑なビジネス要件をSQLに落とし込んだり、データ探索をChatGPTと共同で行うなど、高度な分析テクニックを習得できます。
- ChatGPT利用時のデータセキュリティリスクと、AI生成SQLを確実に検証する重要性、プロンプトエンジニアリングの基本を学び、現場での失敗を防ぎます。
- AIツールと共創する未来のデータアナリスト像を描き、AIリテラシーとSQLスキルを融合させることで、自身の市場価値を高める道筋が見えてきます。
データアナリストの皆様、日々の分析業務お疲れ様です。データドリブン経営が加速する中、データアナリストの役割は重要性を増しています。しかし、複雑なビジネス要件をSQLに落とし込んだり、既存クエリのデバッグ、パフォーマンス最適化といった作業に膨大な時間を費やし、本来の洞察抽出や戦略立案に集中できないという課題に直面している方も少なくないでしょう。
本記事では、この課題に対し、目覚ましい進化を遂げている生成AI「ChatGPT」を強力な味方につける方法を解説します。SQLとChatGPTを組み合わせることで、皆様の分析業務がどのように効率化され、より価値ある仕事に時間を費やせるようになるのか、具体的なハンズオン形式でご紹介してまいります。
データアナリストの課題解決へ:SQLとChatGPTが拓く新境地
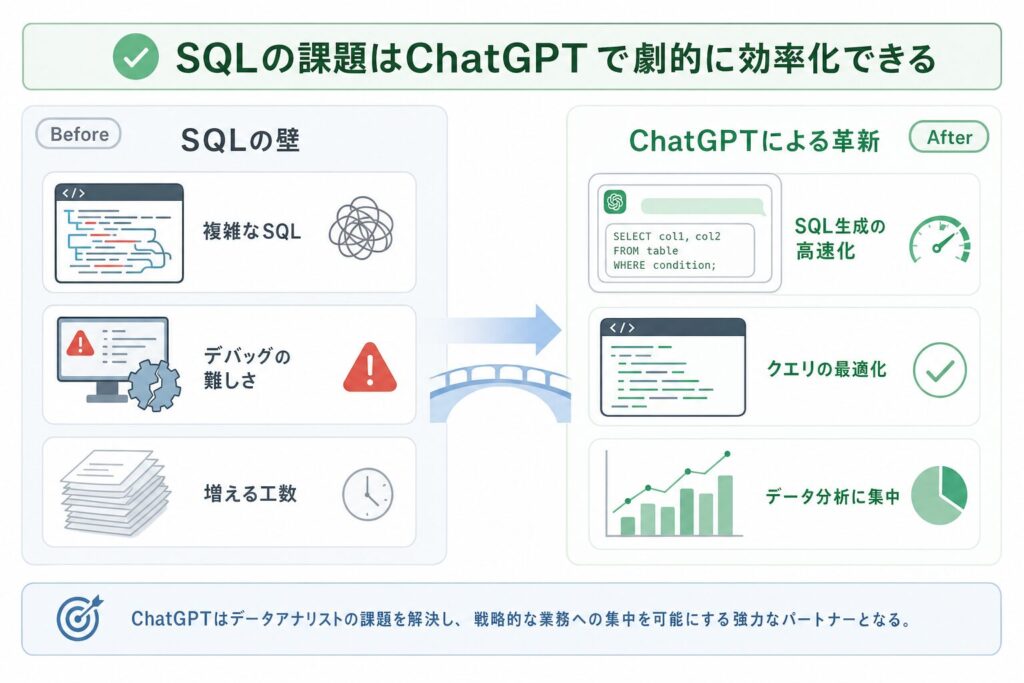
データは現代ビジネスの羅針盤であり、それを読み解くデータアナリストは、企業の意思決定を支える重要な役割を担っています。しかし、その業務には常に課題が伴います。
日常業務に潜む「SQLの壁」:分析工数の増大と複雑性
データアナリストの日常業務において、SQLは最も基本的なツールの一つであり、その習熟度は業務効率に直結します。しかし、SQLにまつわる以下のような課題は、多くのデータアナリストにとって共通の悩みです。
データアナリストが日々の業務で直面する具体的なSQLの課題を見ていきましょう。
データアナリストが直面するSQLの課題
- 複雑なデータ抽出・加工: 複数のデータソースから必要な情報を抽出し、分析に適した形に加工するためのSQLは、しばしば数十行から数百行にも及ぶことがあります。
- クエリのデバッグ: 意図しない結果やエラーが発生した場合、SQLのどの部分に問題があるのかを特定し、修正する作業は時間と労力を要します。特に、大規模なクエリではその難易度が増します。
- パフォーマンスチューニング: 大量のデータを扱う際、非効率なSQLクエリは実行に時間がかかり、システムの負荷を高めます。より高速に結果を得るための最適化は専門的な知識が必要です。
- レポート作成までの工数増大: 分析結果を導き出すためのSQL作成だけでなく、その結果を検証し、レポートとしてまとめるまでの一連のプロセス全体が高い工数となる傾向があります。
- レガシーシステムの対応: 複数のデータベースシステムが混在する環境や、古いシステムとの連携が必要な場合、SQLの構文やデータ型の違いに対応することも課題です。
これらの課題は、データアナリストが本来集中すべき「データからの洞察獲得」や「ビジネス課題解決への貢献」といった戦略的な業務から、多くの時間を奪ってしまいます。結果として、分析サイクルが長期化し、ビジネスの変化への対応が遅れるリスクも生じるのです。
ChatGPTがデータ分析プロセスにもたらす革新
このような「SQLの壁」に直面するデータアナリストにとって、ChatGPTのような大規模言語モデル(LLM: Large Language Model)は、強力な解決策となり得ます。AIの登場は、データ分析プロセスに以下のような革新をもたらし、生産性を向上させる可能性を秘めているのです。
ChatGPTがデータ分析プロセスをどのように変革し得るか、その具体的なメリットをご紹介します。
ChatGPTがもたらすデータ分析プロセスの革新
- SQL生成の高速化: 自然言語で分析の目的を伝えるだけで、ChatGPTが適切なSQLクエリのドラフトを迅速に生成します。これにより、ゼロからクエリを書き始める手間が大幅に削減されます。
- デバッグ支援の強化: エラーメッセージや実行結果をChatGPTに共有することで、問題の原因特定や修正案の提示を迅速に行えます。熟練エンジニアからの助言のように、迅速な問題解決をサポートします。
- クエリ最適化の提案: 非効率なクエリに対して、より高速で効率的な代替案を提案します。インデックスの利用やウィンドウ関数の適用など、専門的な知識を要する最適化もサポートします。
- 探索的データ分析の加速: どのような切り口でデータを見るべきか、どのような統計量を算出するべきかといった、データ探索のアイデア出しや、それに伴うSQL生成をサポートします。
- 学習支援と知識共有: 新しいデータベースやSQL関数を学ぶ際、具体的な使用例や解説をすぐに得られます。また、組織内でのSQL知識の標準化や共有にも役立ちます。
ChatGPTは、単なるSQL生成ツールではありません。データアナリストの思考プロセスをサポートし、煩雑な作業を肩代わりすることで、より高度な分析や戦略的な意思決定に集中できる環境を提供します。これにより、データアナリストは「SQLの書き手」から「ビジネス課題解決の戦略家」へと、その役割を深化させることができるでしょう。
即実践!ChatGPTによるSQL生成・改善の基本ステップ
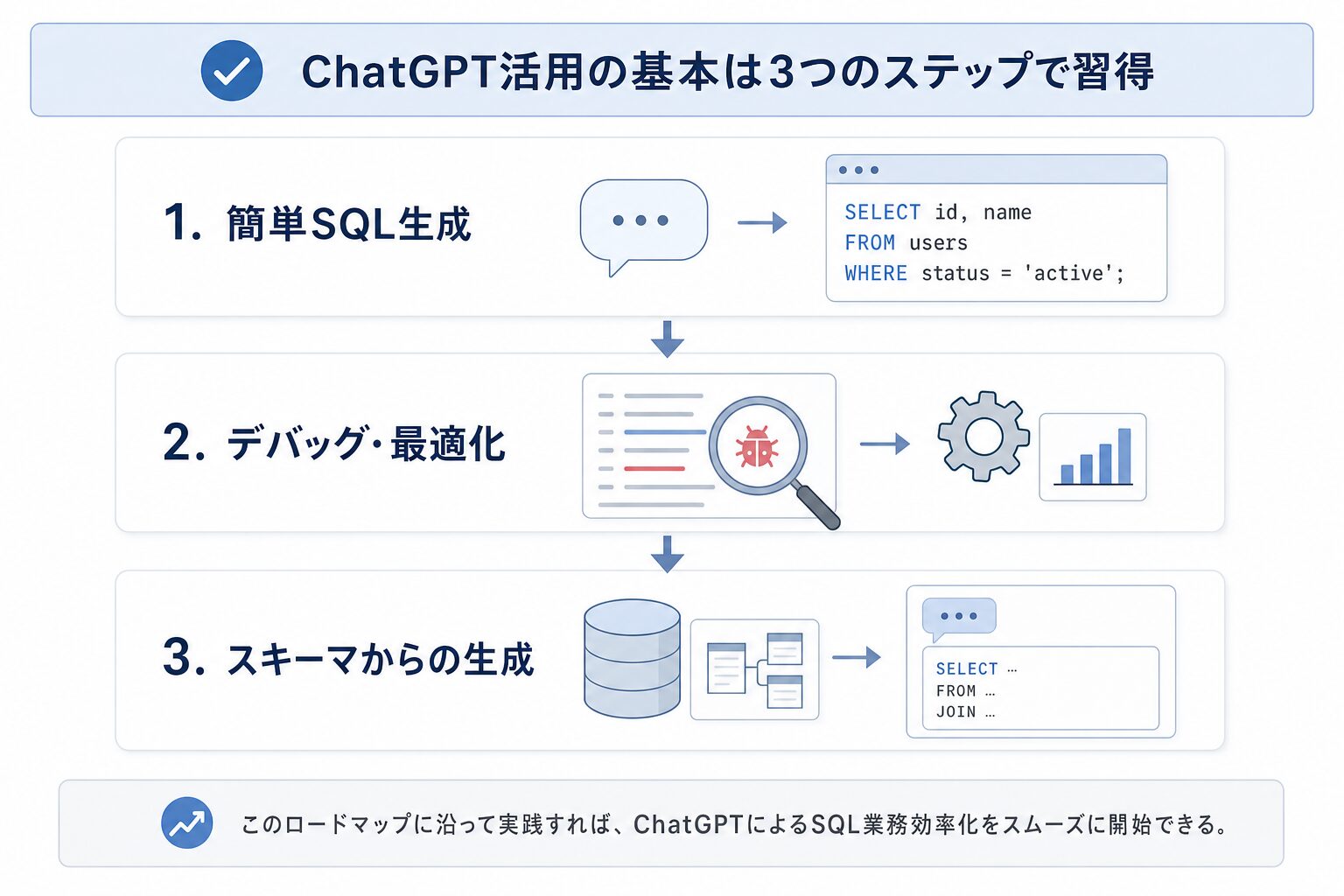
ここからは、実際にChatGPTをデータ分析業務に組み込むための具体的なステップをご紹介します。まずは基本的なSQLの生成から始め、既存クエリのデバッグ、そしてテーブル構造からの自動生成といった応用まで、実践的なプロンプト例とともに解説します。
まずはここから!ChatGPTに簡単なSQLを作成させる
ChatGPTにSQLを生成させる際の基本は、明確な目的と十分な情報を提供することです。テーブル名、カラム名、そして抽出したい条件を具体的に伝えることで、精度の高いSQLを生成できます。
例えば、「`customers` テーブルから、2023年以降に登録された顧客のIDと氏名、登録日を抽出し、登録日の新しい順に並べたい」という要件があるとします。この要件をChatGPTに伝えるプロンプトは以下のようになります。
プロンプト例1:基本的なSELECT文とORDER BY
あなたはデータ分析の専門家です。MySQLの構文で、以下の要件を満たすSQLクエリを作成してください。
テーブル名: `customers`
カラム: `customer_id` (顧客ID), `customer_name` (顧客氏名), `registration_date` (登録日)
要件:
- `customer_id`, `customer_name`, `registration_date` の3カラムを抽出する。
- `registration_date` が2023年1月1日以降の顧客に限定する。
- 結果を `registration_date` の新しい順に並べる。
ChatGPTからの出力例:
SELECT
customer_id,
customer_name,
registration_date
FROM
customers
WHERE
registration_date >= '2023-01-01'
ORDER BY
registration_date DESC;
このプロンプトでは、
- `あなたはデータ分析の専門家です。`:ChatGPTに役割を与えることで、より適切な回答を引き出しやすくなります。
- `MySQLの構文で、`:特定のデータベースシステムを指定することで、構文の差異による問題を回避します。
- `テーブル名:`、`カラム:`、`要件:`:情報を構造化して提示することで、ChatGPTが意図を正確に把握しやすくなります。
次に、複数のテーブルを結合(JOIN)して情報を取得するケースを考えてみましょう。「`orders` テーブルと `products` テーブルを結合し、特定の期間に販売された商品の名称と売上数量を知りたい」という要件です。
プロンプト例2:JOINとWHERE句の組み合わせ
あなたはSQLの専門家です。PostgreSQLの構文で、以下の情報を結合し、指定された期間の売上データを抽出するSQLクエリを作成してください。
テーブル1: `orders`
- カラム: `order_id` (注文ID), `product_id` (商品ID), `order_date` (注文日), `quantity` (数量)
テーブル2: `products`
- カラム: `product_id` (商品ID), `product_name` (商品名), `price` (単価)
結合条件: `orders.product_id` と `products.product_id`
抽出要件:
- `product_name` と `quantity` を抽出する。
- 注文日 (`order_date`) が2023年4月1日から2023年4月30日までのデータに限定する。
ChatGPTからの出力例:
SELECT
p.product_name,
o.quantity
FROM
orders AS o
JOIN
products AS p ON o.product_id = p.product_id
WHERE
o.order_date >= '2023-04-01' AND o.order_date <= '2023-04-30';
このように、ChatGPTは複雑な結合条件や複数条件の絞り込みにも対応したSQLを生成してくれます。プロンプトを具体的に記述することが、期待通りの結果を得るための鍵となります。
既存クエリのデバッグ・最適化を依頼するプロンプト例
既存のSQLクエリがエラーを吐いたり、実行速度が遅かったりする場合、ChatGPTはそのデバッグや最適化の強力な助けとなります。エラーメッセージの解析から、非効率なクエリの改善提案まで、具体的なケーススタディを見ていきましょう。
ケーススタディ1:エラーメッセージの解析と修正
あるSQLクエリを実行したところ、以下のようなエラーメッセージが表示されたとします。
[Error] ORA-00918: column ambiguously defined
このエラーは、SELECT句で指定されたカラムが複数のテーブルに存在し、どちらのテーブルのカラムを参照しているのかが曖昧な場合に発生します。ChatGPTにこのエラーメッセージと、エラーが発生したSQLクエリを提示することで、原因と修正案を尋ねることができます。
プロンプト例3:エラークエリのデバッグ
Oracle Databaseで以下のSQLクエリを実行したところ、「ORA-00918: column ambiguously defined」というエラーが発生しました。このエラーの原因と、それを修正するためのSQLクエリを提案してください。
-- エラーが発生したSQLクエリ
SELECT
customer_id,
customer_name,
order_id,
order_date
FROM
customers c
JOIN
orders o ON c.customer_id = o.customer_id;
ChatGPTからの出力例:
このエラー「ORA-00918: column ambiguously defined」は、SELECT句に指定されたカラム `customer_id` が `customers` テーブルと `orders` テーブルの両方に存在するため、Oracleがどちらのカラムを参照すべきか判断できない場合に発生します。
修正するには、`customer_id` の前にエイリアス(テーブルの別名)を付けて、どちらのテーブルのカラムを参照するか明確にする必要があります。
修正案:
SELECT
c.customer_id, -- customersテーブルのcustomer_idであることを明示
c.customer_name,
o.order_id,
o.order_date
FROM
customers c
JOIN
orders o ON c.customer_id = o.customer_id;
ChatGPTはエラーの原因を正確に特定し、具体的な修正方法を提示してくれました。このように、エラーメッセージの意味が不明な場合や、迅速な修正が必要な場合に非常に役立ちます。
ケーススタディ2:既存クエリのパフォーマンス最適化
大規模なデータセットに対して実行するクエリは、パフォーマンスが重要です。非効率なクエリは、システムリソースを大量に消費し、分析結果の取得に時間がかかります。
プロンプト例4:非効率なクエリの最適化
以下のSQLクエリのパフォーマンス改善案を提案してください。特に、大規模な`transactions`テーブルを扱っており、現在の実行に時間がかかっています。PostgreSQLの構文で、可能な限り効率的な方法を検討してください。
-- 現在の遅いSQLクエリ
SELECT
p.product_name,
SUM(t.amount) AS total_sales
FROM
products p
JOIN
transactions t ON p.product_id = t.product_id
WHERE
t.transaction_date >= '2023-01-01'
GROUP BY
p.product_name
ORDER BY
total_sales DESC;
ChatGPTからの出力例(一部抜粋):
このクエリのパフォーマンスを改善するためのいくつかの提案です。大規模な`transactions`テーブルを扱っているとのことですので、インデックスの活用とクエリ自体の効率化が主な焦点となります。
**提案1:インデックスの確認と追加**
- `transactions`テーブルの`product_id`カラムにインデックスがあるか確認してください。存在しない場合は、作成を検討してください。
`CREATE INDEX idx_transactions_product_id ON transactions (product_id);`
- `transactions`テーブルの`transaction_date`カラムにもインデックスがあるか確認し、必要であれば作成してください。
`CREATE INDEX idx_transactions_transaction_date ON transactions (transaction_date);`
**提案2:クエリの効率化**
現在のクエリは比較的シンプルで、大きな問題は見当たりませんが、WHERE句がJOIN句の前に評価されるようにオプティマイザが働くため、先に日付で絞り込みが行われます。もし`transactions`テーブルが非常に大きく、`transaction_date`の範囲が狭い場合、この部分はすでに効率的です。
ただし、`GROUP BY`句の`product_name`は`products`テーブルから来ています。`product_id`で先にグループ化し、最後に`product_name`を結合する方が、中間結果セットを小さくできる可能性があります。
代替案(CTEを使用):
WITH FilteredTransactions AS (
SELECT
product_id,
amount
FROM
transactions
WHERE
transaction_date >= '2023-01-01'
)
SELECT
p.product_name,
SUM(ft.amount) AS total_sales
FROM
FilteredTransactions ft
JOIN
products p ON ft.product_id = p.product_id
GROUP BY
p.product_name
ORDER BY
total_sales DESC;
この代替案では、CTE(共通テーブル式)を使用して、まず日付でフィルタリングされたトランザクションデータを作成し、その上で`products`テーブルと結合しています。オプティマイザの挙動にもよりますが、大規模データでは中間結果のサイズが小さくなることでパフォーマンスが向上する可能性があります。
**提案3:EXPLAIN ANALYZEの活用**
上記の改善策を適用する前と後に、`EXPLAIN ANALYZE`コマンドを使ってクエリの実行計画と実行時間を比較し、最も効果的な方法を見つけることを強くお勧めします。
例: `EXPLAIN ANALYZE SELECT ...`
ChatGPTは、インデックスの重要性を指摘し、具体的なインデックス作成SQLまで提示しています。さらに、CTEを用いたクエリの代替案まで提案し、それぞれの提案の意図を説明してくれました。最終的には、`EXPLAIN ANALYZE`を活用して実際に効果を検証することの重要性も伝えています。
初学者必見!テーブル構造からのSQL自動生成
データ分析プロジェクトの初期段階や、新しいデータセットに触れる際、テーブルのスキーマ情報から手早く必要なSQLを生成したい場面は多々あります。ChatGPTにテーブル構造を伝えることで、目的のデータを抽出するためのSQLを効率的に生成させることができます。
ここでは、`CREATE TABLE`文を例に、テーブル定義をChatGPTに与えてSQLを生成させる方法を解説します。
プロンプト例5:CREATE TABLE文からのSQL生成
以下のテーブル定義に基づいて、特定の分析要件を満たすSQLクエリをPostgreSQLの構文で作成してください。
-- テーブル定義
CREATE TABLE employees (
employee_id SERIAL PRIMARY KEY,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
phone_number VARCHAR(20),
hire_date DATE NOT NULL,
job_id INTEGER NOT NULL,
salary DECIMAL(10, 2) NOT NULL,
department_id INTEGER
);
CREATE TABLE departments (
department_id SERIAL PRIMARY KEY,
department_name VARCHAR(50) UNIQUE NOT NULL,
location VARCHAR(50)
);
要件:
- 各部署の平均給与と従業員数を算出する。
- 部署名 (`department_name`) と平均給与、従業員数を表示する。
- 平均給与が高い順に結果を並べる。
ChatGPTからの出力例:
SELECT
d.department_name,
AVG(e.salary) AS average_salary,
COUNT(e.employee_id) AS employee_count
FROM
employees AS e
JOIN
departments AS d ON e.department_id = d.department_id
GROUP BY
d.department_name
ORDER BY
average_salary DESC;
このように、詳細なテーブル定義を与えることで、ChatGPTはテーブル間のリレーションシップを理解し、複雑な集計や結合を含むSQLクエリも適切に生成できます。これは、特に複数のテーブルを扱う大規模なデータウェアハウス環境で威力を発揮します。スキーマ情報を直接入力できない場合は、`DESCRIBE table_name;` コマンドの結果や、データディクショナリの情報を貼り付けることでも同様に機能します。初学者にとっては、テーブル構造を理解しながら実践的なSQLを学ぶ上で非常に効果的な方法です。
実務で差をつける!ChatGPTを活用した高度なSQL分析テクニック
ここからは、より複雑なビジネス要件に対応するためのChatGPT活用術をご紹介します。単なるSQL生成に留まらず、データアナリストとしての思考を深め、分析の質を高めるためのテクニックを見ていきましょう。
複雑なビジネス要件をSQLクエリに変換するコツ
実務では、単一の明確なSQL要件が与えられることは稀です。「過去1ヶ月間の新規顧客のうち、特定商品Aを購入し、かつ購入単価が平均以上のリピーターの傾向を分析したい」といった、複数の条件と定義が絡み合う複雑なビジネス要件に直面することがほとんどです。このような要件を直接ChatGPTに投げても、一度で完璧なSQLが得られるとは限りません。
重要なのは、ビジネス要件を小さなステップに分解し、ChatGPTと対話しながら、段階的にSQLを構築していくプロセスです。
ハンズオン:複雑な要件の分解とSQL化
前提となるテーブル構造:
- `customers`: `customer_id`, `registration_date`, `customer_type`
- `orders`: `order_id`, `customer_id`, `order_date`, `product_id`, `quantity`, `price`
- `products`: `product_id`, `product_name`
ビジネス要件: 「過去1ヶ月間の新規顧客のうち、特定商品A(`product_name`=’特定商品A’)を購入し、かつ購入単価が平均以上のリピーターの傾向を分析したい。具体的には、これらの顧客の顧客IDと初回購入日、合計購入金額を抽出したい。」
ステップ1:新規顧客の定義と抽出(ChatGPTに確認しながら)
「新規顧客」の定義は、「分析対象期間の過去1ヶ月間に`registration_date`を持つ顧客」とします。この定義に基づいて、まずは新規顧客のIDを抽出するSQLを作成します。
プロンプトA-1:
あなたはデータアナリストです。以下のテーブル定義に基づいて、過去1ヶ月間(例えば、2023年11月1日から2023年11月30日)に新規登録された顧客のIDを抽出するSQLクエリを作成してください。
テーブル定義:
- `customers`: `customer_id`, `registration_date`
(ChatGPTが新規顧客のSQLを生成)
ステップ2:特定商品Aを購入した顧客の抽出
次に、ステップ1で抽出した新規顧客の中から、さらに特定商品Aを購入した顧客を絞り込みます。必要なテーブル情報を追加して、SQLの修正を依頼します。
プロンプトA-2:
上記で抽出した新規顧客の中から、さらに商品名が「特定商品A」を少なくとも一度は購入した顧客のIDを抽出したいです。以下の追加テーブル情報を使って、SQLを修正してください。
追加テーブル定義:
- `orders`: `order_id`, `customer_id`, `product_id`, `order_date`
- `products`: `product_id`, `product_name`
(ChatGPTがJOINとWHEREで商品A購入者を絞り込むSQLを生成。サブクエリやCTEを使うかもしれません。)
ステップ3:購入単価が平均以上の顧客の抽出
ここでいう「購入単価」は、`orders`テーブルの`price * quantity`で計算される各注文の合計金額とします。この合計金額が、全顧客の平均購入単価(あるいは特定商品Aを購入した顧客の平均購入単価)以上であるという条件を加えます。少し複雑なので、ChatGPTに「平均購入単価の算出SQL」から相談します。
プロンプトA-3:
先ほどのSQLに、条件「購入単価が平均以上」を追加したいです。まず、全顧客の各注文の平均購入単価(`price * quantity`の平均)を算出するSQLクエリを作成してください。
テーブル定義:
- `orders`: `order_id`, `customer_id`, `product_id`, `quantity`, `price`
(ChatGPTがAVG関数を使ったSQLを生成)
その後、この平均単価を先ほどのSQLに組み込む方法を尋ねます。
プロンプトA-4:
上記で算出した平均購入単価を利用して、先ほどの「新規顧客かつ特定商品A購入者」のリストの中から、さらに「各注文の購入単価が全顧客の平均購入単価以上」である顧客のIDを抽出するSQLクエリを提案してください。
(ChatGPTがサブクエリやウィンドウ関数などを用いて結合したSQLを生成)
ステップ4:リピーターの定義と抽出
「リピーター」とは、「特定期間内に複数回購入している顧客」と定義します。最終的に、これらの顧客の`customer_id`、初回購入日、合計購入金額を抽出するSQLを完成させます。
プロンプトA-5:
最後に、「リピーター」という条件を追加したいです。上記で得られた顧客リストの中から、「過去1ヶ月間(2023年11月1日から2023年11月30日)に2回以上商品を購入している顧客」を特定するSQLクエリを完成させてください。最終的に、これらの顧客の`customer_id`、初回購入日 (`order_date`のMIN)、合計購入金額 (`quantity * price`のSUM) を抽出したいです。
(ChatGPTがCOUNT(*)やMIN/SUMとHAVING句を組み合わせた最終的なSQLを生成)
このように、複雑なビジネス要件は一度にSQL化しようとせず、小さな論理単位に分解し、ChatGPTと対話しながら徐々に完成度を高めていくのが効果的です。これにより、最終的なSQLの意図も明確になり、デバッグもしやすくなります。
ChatGPTと共同でデータ探索型SQLを設計する
データ探索型データ分析(EDA: Exploratory Data Analysis)は、未知のデータセットから洞察を得るための重要なプロセスです。どのような角度でデータを見るべきか、どのようなSQLが必要かをゼロから考えるのは時間がかかりますが、ChatGPTは優れたブレインストーミングパートナーとなります。
プロンプト例6:探索的データ分析(EDA)のためのSQL設計
あなたはデータ分析の経験豊富なコンサルタントです。以下のテーブル`web_logs`のデータを使って、ユーザーの行動傾向を探索的に分析したいです。どのようなSQLクエリから始めるべきか、具体的な目的とSQLの例をいくつか提案してください。
テーブル定義:
- `web_logs`: `log_id` (ログID), `user_id` (ユーザーID), `event_timestamp` (イベント日時), `page_url` (アクセスURL), `event_type` (イベントタイプ: 'view', 'click', 'purchase'など), `session_id` (セッションID)
分析のゴール: ユーザーエンゲージメント、サイト内回遊性、コンバージョンパスの傾向を把握したい。
ChatGPTからの出力例(一部抜粋):
はい、承知いたしました。`web_logs`テーブルを用いたユーザー行動分析のための探索的データ分析(EDA)の初期ステップとして、いくつかのSQLクエリをご提案します。これらのクエリを通じて、データの全体像を把握し、具体的な分析の方向性を見つけることができます。
**1. 基本的なデータ概要の把握**
- **目的:** ログデータの期間、ユニークユーザー数、イベントタイプの内訳などを確認し、データの全体像を把握します。
- **SQL例:**
-- ログデータの期間
SELECT
MIN(event_timestamp) AS first_log_date,
MAX(event_timestamp) AS last_log_date
FROM
web_logs;
-- ユニークユーザー数
SELECT
COUNT(DISTINCT user_id) AS unique_users
FROM
web_logs;
-- イベントタイプ別の件数
SELECT
event_type,
COUNT(*) AS event_count
FROM
web_logs
GROUP BY
event_type
ORDER BY
event_count DESC;
**2. ユーザーごとの行動回数とセッション数**
- **目的:** 各ユーザーがどれくらいの頻度でサイトを訪れ、どのような行動をしているか概観します。
- **SQL例:**
SELECT
user_id,
COUNT(DISTINCT session_id) AS total_sessions,
COUNT(log_id) AS total_events
FROM
web_logs
GROUP BY
user_id
ORDER BY
total_sessions DESC
LIMIT 10; -- 上位10ユーザー
**3. よくアクセスされるページ**
- **目的:** どのページがユーザーの関心を引きやすいか、または主要な導線になっているかを確認します。
- **SQL例:**
SELECT
page_url,
COUNT(*) AS page_views
FROM
web_logs
WHERE
event_type = 'view' -- または特定のイベントタイプに限定
GROUP BY
page_url
ORDER BY
page_views DESC
LIMIT 10; -- 上位10ページ
これらの初期クエリから得られた結果を基に、「特定のユーザーグループの行動はどうか?」「コンバージョンに至るまでの一般的なパスは?」「離脱が多いページはどこか?」など、さらに具体的な質問をChatGPTに投げかけながら、深掘りしていくと良いでしょう。
ChatGPTは、分析のゴールから逆算して、段階的にどのようなSQLが必要かを具体例とともに提示してくれました。これにより、データアナリストはゼロから考える時間を大幅に短縮し、より迅速にデータからの洞察獲得へと進むことができます。提案されたSQLを実行し、その結果から次の質問をChatGPTに投げかける、というインタラクティブなプロセスがEDAを加速させます。
パフォーマンスチューニング支援と代替案の提示
大規模データにおけるクエリ遅延は、分析業務のボトルネックとなりがちです。ChatGPTは、クエリの遅延原因の特定から、具体的な改善策の提案まで、パフォーマンスチューニングにおいても強力なサポートを提供します。
プロンプト例7:大規模データ向けクエリのパフォーマンスチューニング
以下のPostgreSQLのSQLクエリが、数百万件のレコードを持つ`sales_history`テーブルに対して非常に遅いです。`EXPLAIN ANALYZE`の結果も合わせて添付します。パフォーマンスを改善するための具体的な提案を複数、理由とともに提示してください。
-- 遅いSQLクエリ
SELECT
c.customer_name,
SUM(sh.amount) AS total_amount_spent
FROM
customers c
JOIN
sales_history sh ON c.customer_id = sh.customer_id
WHERE
sh.sale_date >= '2022-01-01'
GROUP BY
c.customer_name
ORDER BY
total_amount_spent DESC
LIMIT 100;
-- EXPLAIN ANALYZE の結果 (簡略化された架空の例)
-- -> Hash Join (cost=50000.00..80000.00 rows=500000 width=32)
-- Hash Cond: (sh.customer_id = c.customer_id)
-- -> Seq Scan on sales_history sh (cost=0.00..30000.00 rows=1500000 width=16)
-- Filter: (sh.sale_date >= '2022-01-01'::date)
-- -> Hash (cost=40000.00..40000.00 rows=200000 width=20)
-- -> Seq Scan on customers c (cost=0.00..20000.00 rows=200000 width=20)
ChatGPTからの出力例(一部抜粋):
添付された`EXPLAIN ANALYZE`の結果とクエリから、パフォーマンス改善のためのいくつかの提案をいたします。特に大規模テーブル`sales_history`へのアクセスと集計がボトルネックになっている可能性があります。
**提案1:インデックスの最適化**
`EXPLAIN ANALYZE`の結果で`Seq Scan on sales_history`や高コストの`Hash Join`が確認される場合、以下のカラムに適切なインデックスがない可能性が高いです。
- `sales_history.customer_id`: `customers`テーブルとのJOIN条件に使われています。
- `sales_history.sale_date`: WHERE句で範囲指定されています。
- `customers.customer_id`: `sales_history`テーブルとのJOIN条件に使われています。
推奨されるインデックス:
CREATE INDEX idx_sales_history_customer_id ON sales_history (customer_id);
CREATE INDEX idx_sales_history_sale_date ON sales_history (sale_date);
CREATE INDEX idx_customers_customer_id ON customers (customer_id); -- 存在しない場合
**理由:** インデックスは、WHERE句やJOIN句で高速にデータを検索するために不可欠です。`sale_date`の範囲検索や`customer_id`での結合が大幅に高速化されます。
**提案2:CTE(共通テーブル式)の使用による中間結果の絞り込み**
`sales_history`テーブル全体を結合してからフィルタリングするのではなく、先に日付で絞り込んだ後で結合と集計を行うことで、中間結果のデータ量を減らすことができます。
WITH RecentSales AS (
SELECT
customer_id,
amount
FROM
sales_history
WHERE
sale_date >= '2022-01-01'
)
SELECT
c.customer_name,
SUM(rs.amount) AS total_amount_spent
FROM
customers c
JOIN
RecentSales rs ON c.customer_id = rs.customer_id
GROUP BY
c.customer_name
ORDER BY
total_amount_spent DESC
LIMIT 100;
**理由:** `RecentSales` CTEで先に過去のデータを除外することで、`JOIN`や`GROUP BY`の対象となるデータ量が減り、処理負荷を軽減できます。
**提案3:マテリアライズドビューの検討**
もしこのクエリが頻繁に実行され、結果がリアルタイム性をそこまで必要としないのであれば、マテリアライズドビューを作成することで、クエリ実行のたびに再計算する手間を省けます。
CREATE MATERIALIZED VIEW top_100_customers_sales AS
SELECT
c.customer_name,
SUM(sh.amount) AS total_amount_spent
FROM
customers c
JOIN
sales_history sh ON c.customer_id = sh.customer_id
WHERE
sh.sale_date >= '2022-01-01'
GROUP BY
c.customer_name
ORDER BY
total_amount_spent DESC
LIMIT 100;
-- 定期的に更新する場合
REFRESH MATERIALIZED VIEW top_100_customers_sales;
**理由:** クエリの結果を事前に計算して永続化することで、その後のクエリはマテリアライズドビューから高速にデータを取得できます。ただし、データの鮮度と更新頻度のバランスを考慮する必要があります。
これらの提案を一つずつ試して、`EXPLAIN ANALYZE`で効果を確認しながら最適なチューニングを進めることをお勧めします。
ChatGPTは、`EXPLAIN ANALYZE`の結果を踏まえ、インデックスの最適化、CTEを用いたクエリの書き換え、さらにはマテリアライズドビューの活用といった、段階的かつ実践的な改善案を提示してくれました。それぞれの提案には明確な理由が添えられており、データアナリストはこれらの情報をもとに、最適なチューニング戦略を立てることが可能になります。
現場で後悔しないために:ChatGPT利用時の注意点とベストプラクティス

ChatGPTは非常に強力なツールですが、その利用にはいくつかの注意点とベストプラクティスがあります。特に、企業でデータ分析を行うデータアナリストの皆様にとって、データセキュリティと生成されたSQLの品質検証は不可欠です。
データセキュリティと機密情報管理の徹底
ChatGPTのような外部AIサービスを利用する際に最も重要となるのが、データセキュリティと機密情報管理です。安易に個人情報や企業秘密を含むデータを入力してしまうと、情報漏洩のリスクが高まります。
ChatGPT利用時のデータセキュリティを確保するための具体的な対策を以下に示します。
ChatGPT利用時のデータセキュリティ対策
- 個人情報(PII)の匿名化: 顧客名、メールアドレス、電話番号など、個人を特定できる情報は絶対にプロンプトに入力しないでください。可能な限り匿名化されたデータや、仮のデータを使用しましょう。
- 企業秘密・機密情報の回避: 会社の財務データ、未公開の製品情報、顧客リストなど、外部に漏れてはならない情報は入力しないのが鉄則です。
- 利用規約の確認と社内ガイドラインの遵守: 利用しているChatGPTのサービスプロバイダーのデータ利用ポリシーを必ず確認し、データがどのように扱われるかを理解しましょう。また、所属企業のAI利用に関するガイドラインやポリシーがある場合は、それに厳密に従ってください。
- データマスキング・サンプリング: テーブル構造やデータの一部を共有する際も、実際の機密データではなく、マスキング処理されたダミーデータや、極少量で特定が不可能なサンプルデータを用いることを検討してください。
- 社内承認済みツールの活用: 可能であれば、社内でセキュリティレビューをクリアし、承認されたAIツールや、オンプレミス環境で運用されるLLMを利用することが最も安全です。
ChatGPTは学習のためにプロンプトの情報を利用する可能性があります。企業で扱うデータは、その取り扱いに細心の注意を払い、万が一のリスクを最大限に排除する姿勢が求められます。
ChatGPT生成SQLの「必ず検証」が鉄則
ChatGPTが生成するSQLは、非常に精度が高いものですが、完璧ではありません。特に、複雑なビジネスロジックや特定のデータベースの癖、意図しないエッジケースにおいては、誤ったSQLを生成する可能性があります。そのため、AIが生成したSQLは、必ず人間の目で検証し、テスト環境で実行することが不可欠です。
AI生成SQLの品質を確保するための検証チェックリストを以下に示します。
AI生成SQLの検証チェックリスト
- テスト環境での実行: 本番環境に適用する前に、必ず開発環境やテスト環境でSQLを実行し、その動作を確認します。
- 少量データでの結果確認: まずは、影響範囲が少ない少量のデータに対してSQLを実行し、期待通りの結果が得られるか目視で確認します。
- データ整合性の検証: 抽出されたデータが、元のデータソースや他の集計結果と矛盾しないか、データ整合性をチェックします。
- エッジケースの考慮: NULL値の扱い、空データセットの場合、境界値(例:期間の開始日・終了日)など、通常と異なるデータパターンで正しく動作するか確認します。
- パフォーマンスの評価: 特に大規模データに対しては、`EXPLAIN`や`EXPLAIN ANALYZE`を用いて、クエリの実行計画と実行時間を評価し、パフォーマンスが期待通りか確認します。
- ビジネス要件との合致: 生成されたSQLが、ビジネス要件を完全に満たしているか、抜け漏れがないかを再度確認します。
AIはあくまで「道具」であり、最終的な責任はデータアナリスト自身が負います。生成されたSQLを盲目的に信頼せず、常に疑いの目を持って検証する習慣を身につけることが、事故を防ぐための鉄則です。
精度を高めるプロンプトエンジニアリングの基本
より正確で実用的なSQLをChatGPTに生成させるためには、「プロンプトエンジニアリング」のスキルが重要です。適切なプロンプトを作成することで、AIの理解度と出力品質を向上させられます。
効果的なプロンプトエンジニアリングのコツを以下にまとめました。
効果的なプロンプトエンジニアリングのコツ
- 役割付与: 「あなたは経験豊富なデータアナリストです」「あなたはPostgreSQLの専門家です」のように、AIに特定の役割を与えることで、その専門性に基づいた回答を引き出しやすくなります。
- 具体的かつ明確な指示: 曖昧な表現を避け、「どのようなカラムを」「どのような条件で」「どのような順序で」といった具体的な情報を明確に伝えます。
- コンテキストの提供: テーブル定義(`CREATE TABLE`文やカラムリスト)、ビジネスルール、データ型など、SQL生成に必要な背景情報を十分に提供します。
- 制約条件の明示: 「MySQLの構文で」「サブクエリは使わずにCTEを使用してください」「特定のカラムは使用しないでください」など、出力に求める制約や条件を明確に指定します。
- 出力形式の指定: 「SQLクエリのみを出力してください」「コードブロックで囲んでください」など、期待する出力形式を指示することで、視認性の高い結果が得られます。
- 複数ステップでの対話: 複雑な要件の場合、一度に全てを解決しようとせず、小さなステップに分解して対話を進めます。例えば、「まずテーブルAとBを結合するSQLを教えてください。次に、その結果を絞り込む条件を追加してください」のように段階的に指示します。
- 例の提示: 似たようなSQLの例や、期待する出力の例を提示することで、AIの理解を深めることができます。
- フィードバックと修正: 生成されたSQLが期待通りでなかった場合は、「この部分をこのように修正してください」「この条件が抜けています」といった具体的なフィードバックを与え、対話を通じて精度を高めます。
プロンプトエンジニアリングは、ChatGPTを使いこなす上で最も重要なスキルの一つです。これらのコツを意識的に実践することで、ChatGPTを単なるツールとしてではなく、まるで熟練の共同作業者のように活用できるようになります。
未来のデータアナリスト像:AIと共創する分析ワークフロー
ChatGPTの登場は、データアナリストの働き方を大きく変えようとしています。AIを単なる効率化ツールとしてだけでなく、分析の質を高め、自身のキャリアをさらに発展させるためのパートナーとして捉えることが重要です。
SQLスキルとAIリテラシーの融合で広がる可能性
「AIがSQLを書いてくれるなら、SQLスキルは不要になるのか?」という疑問を持つ方もいるでしょう。しかし、その答えは明確に「ノー」です。AIはあくまでツールであり、その出力を評価し、修正し、ビジネス要件に合致させるのは人間の役割です。
AI時代のデータアナリストに求められる具体的なスキルを整理します。
AI時代のデータアナリストに必要なスキル
- SQLの深い理解: AIが生成したSQLの意図を理解し、正しいか否かを判断するためには、SQLの基礎文法からパフォーマンスチューニング、各種関数の知識まで、深い理解が不可欠です。AIが誤ったSQLを生成した場合でも、それを特定し、修正する能力はデータアナリストの核心的なスキルであり続けます。
- データモデリングとスキーマ設計の知識: どのようなテーブル設計が分析に適しているか、効率的なデータ構造とは何かといった知識は、AIに適切なコンテキストを与え、最適なSQLを生成させる上で基盤となります。
- ビジネスドメイン知識: ビジネスの課題や目標を理解し、それを具体的なデータ分析の問いに落とし込む能力は、AIには代替できない人間の強みです。AIはSQLを生成できますが、何を分析すべきかは人間が指示しなければなりません。
- AIリテラシーとプロンプトエンジニアリング: ChatGPTのようなAIツールの特性を理解し、効果的に活用するためのプロンプト作成能力は、新しい必須スキルとなります。AIとの対話を通じて、分析の質とスピードを最大化する力が求められます。
- 批判的思考力と検証能力: AIの出力を鵜呑みにせず、常にその正確性、整合性、ビジネス要件との合致度を批判的に検証する能力は、AIを活用する上で最も重要です。
SQLの深い理解とAIリテラシーを融合させることで、データアナリストはSQL記述に費やしていた時間を大幅に削減し、より高度な分析、洞察抽出、戦略立案といった、付加価値の高い業務に集中できるようになります。これにより、データアナリストは単なる「データ抽出者」から「ビジネス課題解決の戦略家」へと進化し、自身の市場価値を飛躍的に高めることができるでしょう。
次のステップへ:さらなる効率化・自動化への展望
ChatGPTによるSQL生成・改善は、データ分析業務効率化の第一歩に過ぎません。今後は、さらに踏み込んだ効率化・自動化への展望が広がっています。
AIとRPAがデータ分析の未来をどのように変えていくか、その具体的な展望を見ていきましょう。
AIとRPAが拓くデータ分析の未来
- RPAツールとの連携による定型レポート自動化: ChatGPTで生成したSQLをRPA(Robotic Process Automation)ツールと連携させることで、定期的に実行される定型的なデータ抽出、集計、レポート作成プロセスを完全に自動化することが可能です。これにより、データアナリストは月次レポート作成などのルーティンワークから解放され、より戦略的な分析に集中できます。
- LLM API連携による自然言語でのデータ分析インターフェース構築: 大規模言語モデル(LLM)のAPIを自社システムに組み込むことで、非エンジニアのビジネスユーザーでも自然言語で質問を投げかけ、必要なデータや分析結果を直接得られるようなインターフェースを構築することが可能になります。これにより、データ分析の民主化が促進され、組織全体のデータ活用能力が向上します。
- AIによる自動インサイト抽出と可視化: 将来的には、AIがデータから自動的にパターンやトレンドを発見し、インサイトを抽出し、さらにそれをインタラクティブなダッシュボードとして可視化するようなシステムも進化していくでしょう。データアナリストは、AIが生成したインサイトを検証し、ビジネスコンテキストに照らして意味付けを行う役割にシフトしていきます。
- データガバナンスと倫理的なAI活用: AIによるデータ分析の自動化が進むにつれて、データの品質管理、セキュリティ、プライバシー保護といったデータガバナンスの重要性が一層高まります。また、AIのバイアスや倫理的な問題に対する理解と対応も、データアナリストにとって重要な課題となります。
このような未来に向けて、データアナリストの皆様には、SQLスキルを深めつつ、ChatGPTのようなAIツールを積極的に学び、プロンプトエンジニアリングのスキルを磨き、そして将来的な自動化技術やデータガバナンスの知識を身につけていくことが求められます。今からこれらの準備を進めることが、激変するビジネス環境の中で自身の価値を高め、企業の成長に貢献するための鍵となるでしょう。
ChatGPTは、データアナリストの業務を奪うものではなく、むしろその能力を拡張し、よりクリエイティブで戦略的な仕事に集中するための強力な「相棒」となるでしょう。本記事でご紹介した実践的なハンズオンを通して、皆様の分析業務が劇的に効率化され、データからの新しい価値創造へと繋がることを心から願っています。