
目次
本記事のポイント
- AI開発におけるコーディング、デバッグ、品質担保の課題をClaude CodeとGitHub連携でどう解決するか、その全体像を把握できます。
- Claude Codeの基本的な使い方から、GitHubでのバージョン管理、チーム開発の基礎まで、実務に必須の知識を習得できます。
- Claude Codeで生成したコードをGitHubに統合し、プルリクエストやCI/CDパイプラインへ繋げる実践的なAI開発フローを構築する具体的なステップを学べます。
- AI生成コードの品質を確保するためのテストコード自動生成や、プロンプトエンジニアリングの応用テクニックを習得し、開発効率を最大化するヒントを得られます。
- セキュリティやプライバシーに関する考慮事項も含め、Claude CodeとGitHub連携がもたらすビジネスインパクトと今後の展望を理解し、未来のAI開発をリードする道筋を見つけられます。
はじめに:AI開発のボトルネックを解消する「Claude Code × GitHub」の可能性
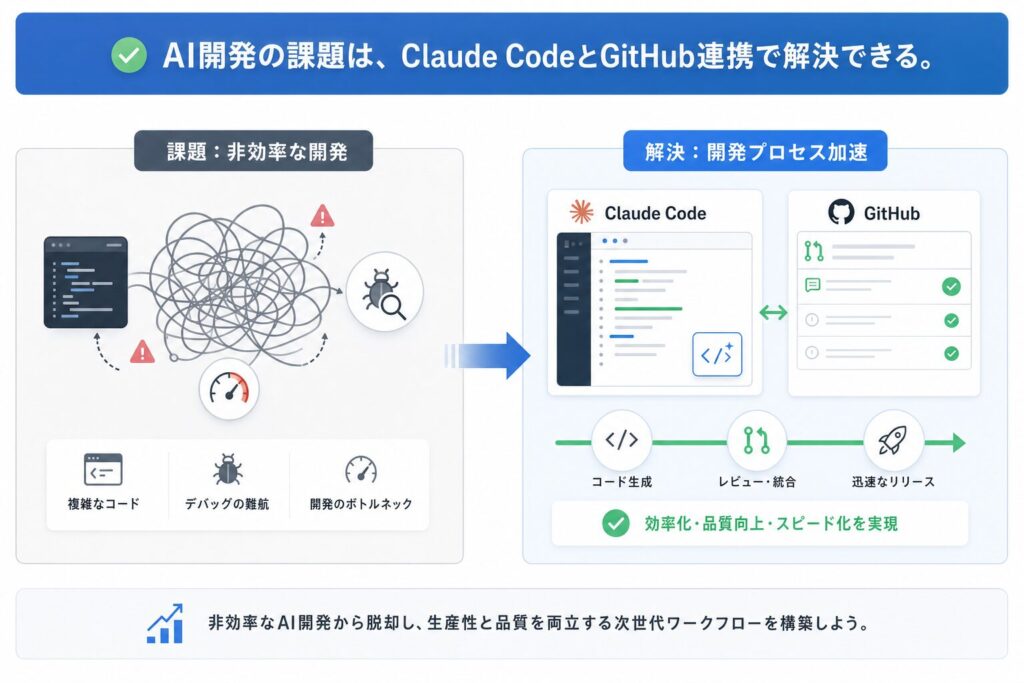
企業のデジタルトランスフォーメーション(DX)推進において、AI技術の活用は不可欠です。しかし、AIモデルの開発から運用までのプロセスは複雑で、多くの企業が効率化に課題を抱えています。特に、高度な専門知識を要するコーディングフェーズでは、開発期間の長期化や品質担保の難しさがボトルネックとなっています。
本記事では、この課題を解決する強力なソリューションとして、Anthropic社の大規模言語モデル「Claude Code」と、世界中で広く利用されているコードホスティングサービス「GitHub」を連携させた、次世代のAI開発フロー構築術を徹底解説します。
AI開発における現状の課題とClaude Codeへの期待
AI開発の現場では、日々新たな技術や手法が生まれていますが、同時に以下の共通課題に直面しています。
ここでは、AI開発における主な課題点を整理します。
AI開発における主な課題
- コード生成の非効率性: 要件定義からコード実装までの手作業が多く、開発に時間を要します。特に、既存コードへの機能追加や大規模なリファクタリングは、多大な労力が必要です。
- デバッグ時間の長期化: 複雑なモデルやデータパイプラインにおけるバグの発見と修正は、専門知識と経験が求められ、開発期間を圧迫する大きな要因です。
- 品質担保の難しさ: コードの品質や保守性を維持しつつ、迅速な開発を進めることは容易ではありません。テストコードの作成不足や、コーディング規約の遵守が徹底されないケースも見られます。
- 専門性の高い知識要求: 最新のAIアルゴリズムやフレームワーク、ライブラリの知識が常に求められ、エンジニアの学習コストが高くなりがちです。
これらの課題に対し、大規模言語モデル(LLM)によるコーディング支援は、新たな解決策として大きな期待が寄せられています。LLMは、自然言語での指示に基づいてコードを生成、修正、最適化する能力を持ち、開発者の生産性を飛躍的に向上させる可能性を秘めています。
特に「Claude Code」は、Anthropic社が開発した高度な推論能力を持つLLMであり、その優れた性能により、複雑なプログラミングタスクにおいても質の高い支援を提供します。要件に応じたコードスニペットの生成、既存コードの分析と改善提案、バグの特定と修正案の提示など、多岐にわたる機能でAI開発のボトルネック解消に貢献します。
GitHub連携がもたらす開発効率と品質向上
Claude Codeがコード生成を革新する一方、開発プロセス全体の効率性と品質担保には、GitHubのような堅牢なバージョン管理システムとの連携が不可欠です。GitHubは単なるコードリポジトリではなく、共同開発、コードレビュー、CI/CD(継続的インテグレーション/継続的デリバリー)パイプライン統合のハブとして機能します。
ここでは、GitHub連携がAI開発にもたらすメリットを解説します。
GitHub連携がもたらすメリット
- 確実なバージョン管理: AI生成コードを含む全ての変更履歴が明確に管理され、いつでも過去の状態に遡ることが可能です。これにより、実験的なコードの試行錯誤も安心して行えます。
- スムーズな共同開発: 複数人での開発において、コードの衝突を最小限に抑え、効率的な並行作業を可能にします。特に、AI開発では複数のモデルやデータ処理を並行して進めることが多いため、その恩恵は大きいでしょう。
- 質の高いコードレビュー体制: プルリクエスト機能を通じて、チームメンバーがAI生成コードの正確性や安全性、コーディング規約への準拠をレビューする仕組みを確立できます。
- CI/CDパイプラインとの統合: コードがリポジトリにプッシュされるたびに、自動テストや静的解析が実行され、品質を常に高い水準で維持できます。これにより、AIモデルのデプロイプロセスも自動化・高速化します。
AI生成コードも、人間が書いたコードと同様に厳格な管理とレビューが求められます。GitHubとの連携は、AI生成コードの信頼性を高め、チーム全体での開発効率と品質向上を強力にサポートする基盤です。
本ガイドで習得できること:実践的なAI開発フロー構築のロードマップ
本ガイドでは、エンジニアの皆様がClaude CodeとGitHubを連携させ、実務で活用できるAI開発フローを構築するための具体的なロードマップを提供します。
- Claude Codeの基本的な機能と開発環境の準備方法を学びます。
- GitHubを活用したバージョン管理とチーム開発の基礎を再確認します。
- Claude Codeで生成したコードをGitHubにプッシュし、プルリクエストを通じてチームでレビューする手順を習得します。
- GitHub Actionsを用いたCI/CDパイプラインにAI生成コードを組み込み、自動テストやデプロイを実践します。
- テストコードの自動生成や高度なプロンプトエンジニアリングなど、さらに開発を加速させる応用テクニックを深掘りします。
この実践ガイドを通じて、皆様のAI開発プロセスがより効率的かつ高品質になり、イノベーション創出を支援します。
Claude Codeの基礎知識と開発環境の準備
AI開発フロー構築の第一歩は、その中心となるClaude Codeの能力を理解し、実際に利用できる環境を整えることです。ここでは、Claude Codeの基本的な機能から、利用開始に必要なアカウント設定、そしてローカル開発環境の準備までを解説します。
Claude Codeの概要とプログラミング支援能力
Claude Codeは、Anthropic社の最新大規模言語モデルであるClaudeシリーズを、プログラミングに特化したモデルです。自然言語の指示を深く理解し、意図に沿った質の高いコードを生成します。
ここでは、Claude Codeが提供する主なプログラミング支援能力をまとめます。
Claude Codeの主なプログラミング支援能力
- 自然言語からのコード生成: 要件定義や仕様書を自然言語で記述するだけで、Python、Java、JavaScript、Go、Rustなど主要なプログラミング言語のコードスニペットや関数、クラスなどを生成します。
- 既存コードの分析とリファクタリング: 既存のコードベースを解析し、可読性向上、パフォーマンス最適化、セキュリティ強化のためのリファクタリング案を提案し、自動的に修正することも可能です。
- バグの特定と修正提案: エラーメッセージやコードの挙動から潜在的なバグを特定し、その原因を分析した上で具体的な修正コードを提示します。
- テストコードの自動生成: 既存の関数やクラスに対して、ユニットテストや結合テストのフレームワークに準拠したテストコードを生成し、品質担保を支援します。
- ドキュメント生成: コードやAPIの利用方法、関数やクラスの役割を説明するドキュメント、コメントを自動で生成し、保守性を向上させます。
Claude Codeは、高い文脈理解能力と推論能力により、単なるパターンマッチングに留まらない、より複雑なロジックを必要とするプログラミングタスクにおいても強力な支援を提供します。これにより、開発者はルーティンワークから解放され、より創造的で戦略的な業務に集中できます。
アカウント作成とAPIキーの取得
Claude Codeを利用するには、まずAnthropic社の公式ウェブサイトでアカウントを作成し、APIキーを取得する必要があります。APIキーは、プログラムからClaude Codeのサービスにアクセスするための認証情報であり、厳重な管理が求められます。
- Anthropicアカウントの作成:
Anthropicのウェブサイトにアクセスし、新規アカウント登録を行います。通常、メールアドレスとパスワードを設定し、利用規約に同意することで登録が完了します。
- APIキーの生成:
アカウント登録後、ダッシュボードまたは設定画面からAPIキーの生成セクションに移動します。新しいAPIキーを生成する際には、通常、キーの名前を設定し、使用目的を明確にすることが推奨されます。生成されたAPIキーは一度しか表示されないことが多いため、安全な場所に控え、直ちに環境変数などに設定してください。
- セキュリティを考慮したAPIキーの管理:
APIキーは認証情報であり、外部に漏洩すると不正利用されるリスクがあります。プログラム内で直接コードに書き込むことは絶対に避けてください。以下の方法で安全に管理することが一般的です。
- 環境変数として設定: オペレーティングシステムの環境変数にAPIキーを設定し、プログラムからはその環境変数を読み込むようにします。
- .envファイルとして管理: プロジェクトルートに`.env`ファイルを作成し、APIキーを記述します。そして、Pythonの`python-dotenv`のようなライブラリを使用して読み込みます。この際、`.env`ファイルはGitの管理対象から除外(`.gitignore`に追記)することが必須です。
- クラウドサービスのシークレット管理: AWS Secrets ManagerやGoogle Secret Managerなど、クラウドプロバイダーが提供するシークレット管理サービスを利用することも、特に本番環境では強力な選択肢となります。
APIキーの適切な管理は、サービスを安全に利用し、予期せぬコスト発生や情報漏洩のリスクを防ぐ上で重要なポイントです。
ローカル開発環境のセットアップ(IDE連携の考慮)
Claude Codeを効率的に利用するためには、使い慣れたローカル開発環境を適切にセットアップすることが推奨されます。ここでは、Pythonを主な開発言語と想定し、VS CodeやPyCharmなどの主要なIDE(統合開発環境)との連携を考慮したセットアップ手順を説明します。
- Python環境の準備:
- Pythonのインストール: 公式サイトから最新のPython 3.xをインストールします。
- 仮想環境の作成: プロジェクトごとに独立したPython環境を構築するために、`venv`や`conda`などの仮想環境ツールを使用します。これにより、プロジェクト間でライブラリの依存関係が衝突するのを防げます。
# venv を使用する場合
python -m venv .venv
source .venv/bin/activate # Windowsの場合は .venv\Scripts\activate
- 必要なライブラリのインストール:
Claude CodeのAPIにアクセスするためには、HTTPリクエストを送信するためのライブラリが必要です。通常は`requests`ライブラリやAnthropicが提供する公式のSDK(Software Development Kit)を使用します。
pip install requests
# または Anthropic 公式 SDK
pip install anthropic
- IDE(統合開発環境)のセットアップ:
- VS Code (Visual Studio Code):
- Python拡張機能をインストールします。
- 仮想環境をVS Codeに認識させ、インタープリターとして設定します(`Ctrl+Shift+P`でコマンドパレットを開き、「Python: Select Interpreter」を選択)。
- コード補完、リンティング、デバッグ機能が有効になります。
- PyCharm:
- 新しいプロジェクトを作成する際に仮想環境を設定するか、既存のプロジェクトにPythonインタープリターを追加します。
- PyCharmは強力なコード解析機能とデバッグ機能を標準で提供しています。
- VS Code (Visual Studio Code):
- APIキーの環境変数設定:
前述の通り、ローカル環境でもAPIキーは環境変数として設定することが最善です。
# Linux/macOS の場合 (一時的)
export ANTHROPIC_API_KEY="your_api_key_here"
# または .bashrc, .zshrc などに恒久的に設定
Pythonコード内では、`os.environ.get(‘ANTHROPIC_API_KEY’)`などで取得できます。
これらの準備が整えば、Claude Codeを呼び出すPythonスクリプトを記述し、ローカル環境で試行錯誤を開始できる状態になります。
GitHubを活用したバージョン管理とチーム開発の基礎
AI開発において、コード生成を加速させるClaude Codeの導入は非常に有効ですが、その効果を最大限に引き出し、持続的な開発を可能にするためには、GitHubを基盤とした堅牢なバージョン管理とチーム開発の仕組みが不可欠です。ここでは、GitHubの基本機能と、AI開発におけるその重要性について解説します。
GitHubの基本機能とAI開発における重要性
GitHubは、Gitという分散型バージョン管理システムをウェブ上で提供するサービスであり、コードの履歴管理、共同開発、プロジェクト管理のための多岐にわたる機能を提供します。
GitHubの主要機能とAI開発における関連性について見ていきましょう。
GitHubの主要機能とAI開発における関連性
- リポジトリ (Repository):
プロジェクトの全てのファイル(ソースコード、設定ファイル、ドキュメントなど)とその変更履歴をまとめて保存する場所です。AI開発においては、モデルのコード、データ処理スクリプト、設定ファイル、学習済みモデルのバージョン管理など、プロジェクトの「全て」を格納する中心となります。
- コミット (Commit):
ファイルの変更をリポジトリに記録する操作です。変更内容、作成者、タイムスタンプ、変更理由(コミットメッセージ)が含まれます。AI開発では、モデルのパラメータ変更、データセットの前処理方法の変更、AI生成コードの取り込みなど、意味のある変更ごとにコミットを作成し、履歴を詳細に残すことが重要ですし、後から追跡しやすいようにします。
- ブランチ (Branch):
メインの開発ライン(通常は`main`または`master`ブランチ)から分岐し、独立した開発を進めるための機能です。新しい機能開発、バグ修正、AIモデルの異なるアーキテクチャの実験など、並行して複数のタスクを進める際に利用します。これにより、メインラインに影響を与えずに安全に開発を進められます。
- プルリクエスト (Pull Request / PR):
ブランチでの変更内容をメインの開発ラインに統合(マージ)する前に、チームメンバーにレビューを依頼する機能です。AI生成コードの品質、ロジックの正確性、セキュリティ、コーディング規約への準拠などを確認する重要なプロセスです。コメントや提案を通じて議論し、より良いコードに磨き上げてからマージすることで、コードの品質と信頼性を高めます。
AI開発では、実験的な試行錯誤が多く、コードや設定が頻繁に変更される傾向にあります。GitHubのこれらの機能を活用することで、変更履歴を明確にし、複数の開発者が効率的に協力し、コードの整合性を維持しながら、高品質なAIシステムを構築できます。
リポジトリの作成と初期設定
GitHubを活用したAI開発を開始するには、まずプロジェクトのリポジトリを作成し、初期設定を行います。
- 新規リポジトリの作成:
GitHubのウェブサイトにログインし、「New repository」ボタンをクリックします。
- Repository name: プロジェクトの名前を設定します。
- Description: プロジェクトの概要を記述します。
- Public/Private: プロジェクトを公開するか非公開にするかを選択します。企業のAI開発では通常Privateを選択します。
- Initialize this repository with a README: チェックを入れると、プロジェクトの概要を記述する`README.md`ファイルが自動で作成されます。
- Add .gitignore: 開発言語やフレームワークに応じて、Gitの管理対象から除外したいファイルを指定する`.gitignore`ファイルを自動生成できます。Pythonプロジェクトであれば「Python」を選択します。
- Choose a license: 必要に応じてライセンスを選択します。
これらの設定を終えたら、「Create repository」をクリックしてリポジトリを作成します。
- 既存プロジェクトのインポートまたはローカルとの連携:
- 既存のローカルプロジェクトをGitHubにプッシュする場合:
ローカルのプロジェクトディレクトリで以下のコマンドを実行します。
git init # Gitリポジトリを初期化
git add . # 全てのファイルをステージング
git commit -m "Initial commit" # コミット
git branch -M main # デフォルトブランチ名をmainに設定
git remote add origin https://github.com/your_username/your_repository.git # リモートリポジトリを追加
git push -u origin main # リモートリポジトリにプッシュ
- GitHubからクローンする場合:
GitHubで作成したリポジトリをローカルにクローンして開発を開始します。
git clone https://github.com/your_username/your_repository.git
cd your_repository
- `.gitignore`ファイルによる不要ファイルの除外設定:
`.gitignore`ファイルは、Gitの管理対象に含めたくないファイルやディレクトリを指定するための重要な設定ファイルです。AI開発では、以下のようなファイルを記述することが一般的です。
- 仮想環境ディレクトリ: `venv/`, `.venv/`
- 学習済みモデルファイル: `*.h5`, `*.pth`, `*.pkl` (巨大なファイルはGit LFSの利用も検討)
- データセット: `data/`, `datasets/` (巨大なデータセットは別途管理)
- ログファイル: `logs/`, `*.log`
- 環境変数ファイル: `.env`
- 一時ファイル: `__pycache__/`, `*.pyc`
- IDEの設定ファイル: `.idea/`, `.vscode/`
適切に`.gitignore`を設定することで、リポジトリの肥大化を防ぎ、機密情報の誤った公開を防ぐとともに、開発者のローカル環境に依存するファイルを共有しないことで、スムーズな共同開発を促進します。
ブランチ戦略の選定とプルリクエストフロー
効果的なチーム開発とコード品質の維持には、明確なブランチ戦略とプルリクエストを通じたレビューフローが不可欠です。
- 一般的なブランチ戦略の選定:
代表的なブランチ戦略には「Git Flow」と「GitHub Flow」があります。
- Git Flow:
`master`(本番リリース)、`develop`(開発メイン)、`feature`(機能開発)、`release`(リリース準備)、`hotfix`(緊急修正)といった複数の長期ブランチを持つ、比較的厳格なモデルです。大規模なプロジェクトや、頻繁なリリースサイクルを持たない場合に適しています。
- GitHub Flow:
`main`(本番リリース可能)を常に安定した状態に保ち、機能開発やバグ修正は全て`main`から派生した短い寿命の`feature`ブランチで行い、プルリクエストを通じて`main`にマージします。シンプルで継続的デリバリー(CD)に適しており、多くのAI開発チームで採用されます。
AI開発では、迅速な実験とデプロイが求められることが多いため、シンプルで高速な開発サイクルをサポートするGitHub Flowが推奨されます。
- プルリクエストフロー:
GitHub Flowを例に、プルリクエストを通じた開発フローを説明します。
- ブランチの作成: `main`ブランチから新しい機能開発やバグ修正のためのブランチを作成します(例: `git checkout -b feature/new-model-architecture`)。
- コードの変更とコミット: このブランチ上で開発を進め、Claude Codeで生成されたコードを含め、変更内容を適宜コミットします。
- プルリクエストの作成: 開発が一段落したら、GitHub上で`feature/new-model-architecture`ブランチから`main`ブランチへのプルリクエストを作成します。ここで変更内容の概要、目的、関連する課題などを詳細に記述します。
- コードレビュー: チームメンバーがプルリクエストの内容を確認し、AI生成コードの正確性、効率性、安全性、コーディング規約への準拠、テストカバレッジなどをレビューします。コメントや提案を通じて、改善点があれば修正を依頼します。
- マージ: レビューが承認され、必要な修正が全て完了したら、`feature`ブランチの変更内容を`main`ブランチにマージします。これにより、新たな機能や修正が本番環境にデプロイ可能な状態になります。
このフローを徹底することで、AI生成コードの品質をチーム全体で担保し、安定したAIシステムの開発・運用を実現します。
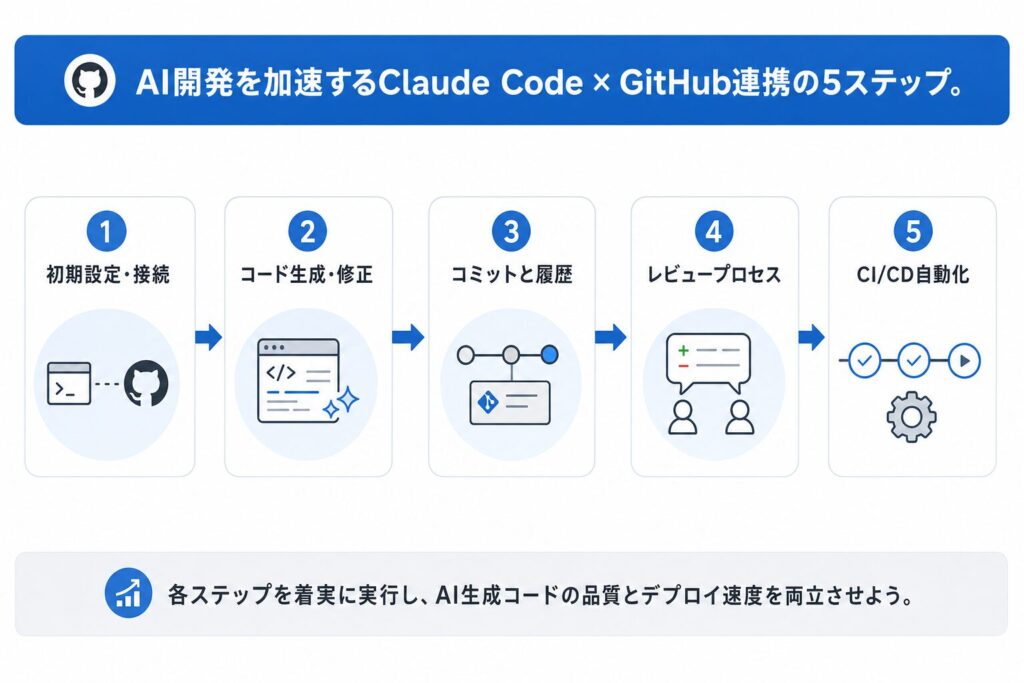
実践!Claude CodeとGitHub連携によるAI開発フロー構築
ここからは、実際にClaude CodeとGitHubを連携させ、AI開発フローを構築する具体的なステップを解説します。各ステップで実務での利用イメージを持ちながら読み進めてください。
Step 1: GitHubリポジトリへのClaude Codeの初期設定と接続
Claude Codeをプロジェクトに組み込む最初のステップは、GitHubリポジトリで管理されているプロジェクトからClaude CodeのAPIに安全にアクセスできるように設定します。
- プロジェクトへのClaude Codeの組み込み方:
Pythonプロジェクトの場合、Claude CodeのAPIとやり取りするクライアントスクリプトを作成します。
例えば、`claude_client.py`のようなファイルを作成し、以下の擬似コードのようにAPIリクエストを行う関数を定義します。
import os
import anthropic # 公式SDKを使用する場合
def generate_code_with_claude(prompt: str) -> str:
api_key = os.environ.get("ANTHROPIC_API_KEY")
if not api_key:
raise ValueError("ANTHROPIC_API_KEY環境変数が設定されていません。")
client = anthropic.Anthropic(api_key=api_key)
response = client.completions.create(
model="claude-2", # 利用するClaudeモデルを指定
prompt=f"{anthropic.HUMAN_PROMPT} {prompt}{anthropic.AI_PROMPT}",
max_tokens_to_sample=2000,
)
return response.completion
if __name__ == "__main__":
# サンプルとして、簡単なPython関数の生成を指示
sample_prompt = "与えられた数値リストの平均値を計算するPython関数を書いてください。関数名は `calculate_average` とし、入力は `numbers: list[float]`、出力は `float` としてください。ドキュメントストリングも追加してください。"
generated_code = generate_code_with_claude(sample_prompt)
print("--- Generated Code ---")
print(generated_code)
print("----------------------")
このスクリプトは、指定されたプロンプトに基づいてClaude Codeにコード生成を依頼し、結果を返します。
- 認証情報の安全な管理と環境変数の活用:
前述の通り、APIキーは環境変数として管理することが最善です。
開発環境では、ターミナルで一時的に設定するか、`.env`ファイルを利用して設定します。
# ターミナルで一時的に設定する場合 (セッション終了まで有効)
export ANTHROPIC_API_KEY="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
本番環境やCI/CD環境では、GitHub Secretsなどのセキュリティ機能を使ってAPIキーを安全に格納し、CI/CDパイプラインから参照するようにします。これにより、機密情報がリポジトリ内に直接記述されることを防げます。
Step 2: Claude Codeを用いたコード生成とリファクタリング
Claude CodeがAPI経由で利用可能になったら、いよいよAIにコード生成や既存コードのリファクタリングを指示します。
- プロンプトエンジニアリングによる効率的なコード生成指示:
Claude Codeは自然言語を理解しますが、より具体的で明確な指示を与えることで、期待通りの高品質なコード生成に繋がります。これを「プロンプトエンジニアリング」と呼びます。
効果的なプロンプトの例を以下に示します。
効果的なプロンプトの例
- 要件の明確化: 「目的、入力、出力、エラー処理」を具体的に記述します。
例: 「ユーザーから入力された文字列が回文であるかを判定するPython関数`is_palindrome(text: str) -> bool`を作成してください。大文字小文字は区別せず、記号やスペースは無視してください。」
- 制約条件の指定: 「特定のライブラリの使用、パフォーマンス要件、セキュリティ要件」などを明記します。
例: 「この関数はNumPyライブラリのみを使用し、100万件のデータに対して1秒以内に処理を完了するように最適化してください。」
- 出力形式の指定: 「クラス形式、関数形式、特定のコメントスタイル」などを指示します。
例: 「生成されるコードは、PEP 8ガイドラインに準拠し、各関数の冒頭にDocstringを追加してください。」
- Few-shot Prompting: 望ましい出力形式の例をいくつか提示することで、Claude Codeが意図をより正確に理解しやすくなります。
`claude_client.py`を呼び出す形で、生成したいコードのプロンプトを渡します。例えば、新しいデータ前処理関数が必要な場合、詳細な要件をプロンプトとして記述します。
- 既存コードのリファクタリング提案と自動適用:
Claude Codeは、既存のコードベースに対しても強力な支援を提供します。
- リファクタリング指示の例:
「以下のPythonコードを分析し、可読性を向上させ、冗長な部分を削減してください。また、関数が大きすぎる場合は複数の小さな関数に分割する提案もしてください。」と、既存のコードブロックをプロンプトに含めてClaude Codeに渡します。
- 自動適用(手動確認必須):
Claude Codeが提案するリファクタリング案は、そのままプロジェクトに適用することも可能ですが、必ず人間の開発者が内容をレビューし、意図しない変更や副作用がないかを確認することが重要です。特に大規模な変更の場合は、テストを十分に実行し、既存の機能が損なわれていないことを確認してください。
Step 3: Gitコマンドを通じた変更のステージングとコミット
Claude Codeで生成・修正されたコードは、GitHubでのバージョン管理プロセスに沿って適切に記録すべきです。
- Claude Codeで生成・修正されたコードのレビュー:
AIが生成したコードは、あくまで「提案」として捉え、必ず人間が目視でレビューします。
- 正確性: 要求通りに機能するか。
- 効率性: パフォーマンスに問題はないか。
- 可読性: チームのコーディング規約に沿っているか、他の開発者が理解しやすいか。
- セキュリティ: 潜在的な脆弱性がないか。
- 冗長性: 不要なコードや複雑すぎるロジックがないか。
必要に応じて手動で修正・改善を加えます。
- 適切なコミットメッセージの作成と履歴管理:
レビューと修正が完了したら、変更内容をGitにコミットします。この際、コミットメッセージは極めて重要です。
コミットメッセージ作成のポイントを以下にまとめます。
コミットメッセージ作成のポイント
- 簡潔かつ具体的: 変更の目的と内容を明確に記述します。
- AI生成コードである旨の記載: 必要に応じて、「feat: Add new preprocessing function (generated by Claude Code)」のように、AIが関与したことを明記すると、後で履歴を追う際に役立ちます。ただし、全てのAI生成コードに明記する必要はなく、重要な変更や、AIの支援が主たる部分を占める場合に限定することも検討します。
- 一貫性: チームでコミットメッセージの書式ルールを定めることで、履歴の可読性が向上します。
以下のGitコマンドで、変更をステージングし、コミットします。
git add src/data_processor.py # 変更されたファイルをステージング
git commit -m "feat: 新しいデータ前処理関数を追加 (Claude Codeで生成)" # コミット
定期的にコミットを行うことで、細かい変更履歴が残り、問題発生時に原因特定やロールバックが容易になります。
Step 4: プルリクエストの作成とコードレビュープロセス
コミットされた変更をメインのブランチに統合する前に、GitHubのプルリクエスト機能を用いてチームメンバーによるレビューを行います。これはAI生成コードの品質と信頼性を確保する上で最も重要なプロセスです。
- GitHub上でのプルリクエスト作成手順:
- 自身の開発ブランチ(例: `feature/new-preprocessing`)にプッシュした後、GitHubのウェブサイトにアクセスします。
- リポジトリのページで「Pull requests」タブをクリックし、「New pull request」ボタンをクリックします。
- 比較元のブランチ(`feature/new-preprocessing`)と、比較先のブランチ(通常は`main`または`develop`)を選択します。
- プルリクエストのタイトルと詳細な説明を記述します。変更内容、目的、Claude Codeの使用状況、特定のレビューを依頼したい点などを明記します。関連するIssueやタスクへのリンクも追加すると良いでしょう。
- レビューアをアサインし、「Create pull request」をクリックします。
- チームメンバーによるAI生成コードのレビューポイントと効率化:
レビューアは、Claude Codeが生成したコードであることを認識した上で、以下の点を重点的に確認します。
AI生成コードのレビューポイントは以下の通りです。
AI生成コードのレビューポイント
- 要求との整合性: プロンプトで指示した内容が正確にコードに反映されているか。意図しない解釈や追加機能がないか。
- ロジックの正しさ: アルゴリズムが正しく実装されており、期待通りの結果を生成するか。エッジケースに対する考慮があるか。
- 効率性とパフォーマンス: 処理速度やメモリ使用量に問題がないか。特に大規模データ処理の場合、ボトルネックとなる部分がないか。
- セキュリティ: 潜在的な脆弱性(インジェクション、情報漏洩など)がないか。
- 可読性と保守性: コーディング規約(PEP 8など)に準拠しているか。コメントやDocstringが適切に記述されており、コードが理解しやすいか。
- テストカバレッジ: 新しい機能や修正が十分なテストコードでカバーされているか。AIが生成したテストコードが適切か。
レビュー効率化のヒント:
- 特定のセクションに焦点を当てる: 大量のコードが生成された場合、全ての行を詳細にレビューするのは困難です。特に複雑なロジックやセキュリティに関わる部分に焦点を当てるようにレビューアに依頼します。
- AIの出力限界を理解する: AIは完璧ではありません。特定のドメイン知識や最新のベストプラクティスを補完する形で人間が介入する意識が重要です。
- 自動化ツールとの連携: リンターや静的解析ツールをCI/CDに組み込むことで、基本的なコーディング規約違反やバグは自動的に検出させ、レビューアはより高度なロジックや設計に集中できるようにします。
レビュープロセスを通じて、AI生成コードの品質が向上し、コードベース全体の信頼性を高めます。
Step 5: CI/CDパイプラインとの連携(GitHub Actionsの活用)
AI開発の最終段階として、Claude Codeで生成されたコードを含む変更が、自動的にテストされ、検証され、場合によってはデプロイされるCI/CD(継続的インテグレーション/継続的デリバリー)パイプラインを構築します。GitHub Actionsは、GitHubリポジトリに直接統合されたCI/CDサービスであり、この目的を達成するための強力なツールです。
- AI生成コードに対する自動テスト、リンティング、デプロイ:
CI/CDパイプラインを導入することで、開発者がコードをプッシュするたびに、以下の自動化されたプロセスが実行されます。
- 自動テスト: ユニットテスト、結合テスト、回帰テストなどを実行し、AI生成コードを含む変更が既存の機能を破壊していないか、新しい機能が正しく動作するかを確認します。
- リンティングと静的解析: コーディング規約(PEP 8など)に準拠しているか、潜在的なバグやセキュリティ脆弱性がないかを自動でチェックします。Flake8、Black、Pylint、Banditなどのツールが活用されます。
- デプロイ: テストと解析に合格したコードは、ステージング環境や本番環境に自動的にデプロイされます。これにより、AIモデルの更新や新機能の市場投入が迅速化します。
- GitHub Actionsによるワークフローの構築例:
GitHub Actionsのワークフローは、リポジトリ内の`.github/workflows`ディレクトリにYAML形式で定義されます。以下に、簡単なPythonプロジェクトにおけるCI/CDワークフローの例を示します。
# .github/workflows/main.yml
name: CI/CD for AI Development
on:
push:
branches:
- main
- feature/* # featureブランチへのプッシュでもCIを実行
jobs:
build-and-test:
runs_on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Set up Python environment
uses: actions/setup-python@v4
with:
python-version: '3.9' # 使用するPythonのバージョン
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt # プロジェクトの依存関係をインストール
pip install flake8 pytest black # リンターとテスターをインストール
- name: Lint code with Flake8 and Black
run: |
flake8 . --max-line-length=120
black --check . # フォーマットチェックのみ
- name: Run unit tests with Pytest
run: |
pytest # プロジェクトのテストを実行
deploy-to-staging:
needs: build-and-test # テストジョブが成功した場合のみ実行
runs_on: ubuntu-latest
environment: Staging # デプロイ環境の指定 (GitHub Environments)
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Set up AWS CLI (or other cloud provider CLI)
uses: aws-actions/configure-aws-credentials@v2
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} # GitHub SecretsからAWS認証情報を取得
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ap-northeast-1
- name: Deploy to S3 (example)
run: |
aws s3 sync . s3://your-staging-bucket/ --exclude ".git/*" --exclude "node_modules/*"
# ここにAIモデルのデプロイやサーバーレス関数の更新などのコマンドを記述
このワークフローでは、コードが`main`または`feature/*`ブランチにプッシュされるたびに、以下の処理が実行されます。
- コードのチェックアウト
- Python環境のセットアップと依存関係のインストール
- Flake8とBlackによるリンティング(コード品質・スタイルチェック)
- Pytestによるユニットテストの実行
- 上記のステップが全て成功した場合、AWS S3へのデプロイ(ステージング環境へのCI/CD例)
Claude Codeで生成されたコードも、このパイプラインを通じて自動的に検証されるため、継続的な品質維持を実現します。GitHub Secretsを活用することで、APIキーやクラウド認証情報などの機密情報を安全に管理しながらCI/CDを構築できる点も大きなメリットです。
より高度なAI開発を加速する応用テクニック

Claude CodeとGitHubの基本的な連携を確立した後、さらにAI開発プロセスを加速し、品質を高めるための応用テクニックをいくつかご紹介します。これらのテクニックを習得することで、より複雑な開発課題にも対応できるようになるでしょう。
Claude Codeによるテストコードの自動生成と品質担保
AI生成コードの品質を担保するためには、適切なテストが不可欠です。Claude Codeは、単に機能コードを生成するだけでなく、そのコードに対するテストコードも自動で生成する能力を持っています。
- ユニットテスト、結合テストの効率的な作成:
- ユニットテストの生成: 特定の関数やクラスの動作を検証するユニットテスト(例: Pythonの`pytest`フレームワーク)をClaude Codeに生成させます。
プロンプト例: 「以下のPython関数`calculate_average`に対するユニットテストを`pytest`形式で作成してください。正常系、空リスト、単一要素のリスト、ゼロを含むリストなど、複数のシナリオをカバーしてください。」と、既存の関数コードと共に指示します。
- 結合テストの補助: 複数のコンポーネントが連携して動作するかを確認する結合テストにおいても、テストデータ生成やモックオブジェクトの作成に関するコードスニペットをClaude Codeに依頼することで、テスト作成の労力を削減できます。
- テストカバレッジの向上とバグの早期発見:
- テストカバレッジの分析: テストコードがどの程度元のコードをカバーしているか(テストカバレッジ)を測定し、カバレッジが低い部分をClaude Codeに伝えて、追加のテストケースを生成させることができます。
- バグの早期発見: テストコードの自動生成とCI/CDパイプラインへの組み込みにより、新しいコードがプッシュされるたびに自動でテストが実行されます。これにより、バグが開発プロセスの早期段階で発見され、修正コストを大幅に削減できます。特に、AI生成コードは人間の開発者が予期しない挙動を示す可能性もあるため、広範囲なテストカバレッジは不可欠です。
プロンプトエンジニアリングによるClaude Codeの活用最大化
Claude Codeの性能を最大限に引き出す鍵は、効果的な「プロンプトエンジニアリング」にあります。単一のシンプルな指示だけでなく、より高度なテクニックを駆使することで、複雑な開発タスクもAIに任せられるようになります。
- より複雑な要件定義をAIに理解させるためのプロンプト設計:
- 構造化されたプロンプト: XMLタグやJSON形式などを用いて、プロンプト内で明確なセクションを定義し、Claude Codeに各情報の役割を理解させやすくします。
例: `<task>…</task>`, `<context>…</context>`, `<output_format>…</output_format>`
- 段階的な指示(Chain-of-Thought Prompting): 複雑なタスクを複数の小さなステップに分割し、Claude Codeに各ステップごとに思考プロセスを示すように指示します。「まず、この問題の構成要素を洗い出してください。次に、それぞれの要素に対して解決策を検討してください。最後に、これらを統合したコードを作成してください。」といった形で、思考の連鎖を促します。
- 役割の割り当て: Claude Codeに特定の役割(例: 「あなたは熟練のPythonエンジニアです」)を割り当てることで、その役割に合わせた視点や専門知識に基づいて回答を生成させます。
- 複数ステップにわたる開発タスクの自動化:
- 反復的な開発プロセス: 初期のコード生成から、リファクタリング、テストコードの追加、ドキュメント生成までの一連のプロセスを、Claude Codeへの連続的なプロンプトとして設計し、自動化スクリプトに組み込むことが可能です。
- コード生成のパイプライン化: 特定の設計パターンやテンプレートに基づいて、複数の関連ファイルを一括で生成するようなスクリプトを作成することで、アプリケーションの骨格部分をAIに任せ、開発者はより高度なロジックの実装に集中できます。
- エラーからの学習と改善: 生成されたコードがコンパイルエラーやテスト失敗を起こした場合、そのエラーメッセージをClaude Codeにフィードバックし、修正案を再生成させることで、反復的なデバッグプロセスを効率化できます。
セキュリティとプライバシーに関する考慮事項
AIを活用した開発では、セキュリティとプライバシーが極めて不可欠です。Claude CodeとGitHubを連携させる際にも、これらの側面に対する深い理解と適切な対策が求められます。
- 機密情報を含むコードの取り扱い:
- APIキーの管理徹底: 前述の通り、Claude CodeのAPIキーや、その他のクラウドサービスの認証情報は、環境変数やGitHub Secretsなどを用いて安全に管理し、決してコード内に直接記述しないようにします。
- コード内の機密情報の匿名化: Claude Codeに機密性の高いビジネスロジックや顧客情報を含むコードを渡す必要がある場合、可能な限りその情報を匿名化・抽象化してからAIに入力すべきです。AIモデルへの入力データは、学習やログとして利用される可能性があるため、機密情報の漏洩リスクを最小限に抑える必要があります。
- GitHubのプライベートリポジトリ: 企業のAI開発プロジェクトは、常にプライベートリポジトリで管理し、アクセス権限を最小限に制限します。
- AIモデルへの入力データに関するポリシー遵守:
- Anthropicのデータ利用ポリシーの確認: Claude Codeに送信されたデータが、どのように利用され、保存されるのかをAnthropic社の公式ポリシーで必ず確認します。特に、入力データがモデルの学習に利用される可能性がある場合は、社内ポリシーや法規制(GDPR、CCPA、個人情報保護法など)との整合性を慎重に検討する必要があります。
- 契約とNDAの確認: 企業としてClaude Codeを利用する場合、Anthropic社との契約内容(NDA: 機密保持契約を含む)を確認し、データ利用に関する条項を理解しておくことが重要です。
- 内部監査とコンプライアンス: AI生成コードが法規制や社内ガイドラインに準拠しているか、定期的に内部監査を実施し、コンプライアンス体制を確立することが望ましいです。特に、AIモデルの出力が差別的、不公平、あるいは倫理的に問題のある内容を含まないか、継続的な監視と評価が求められます。
これらのセキュリティとプライバシーに関する考慮事項は、AI開発の信頼性を確保し、企業のレピュテーションリスクを回避するために不可欠です。
まとめ:未来のAI開発をリードするチームのために
本ガイドでは、Claude CodeとGitHubを連携させることで、AI開発のボトルネックを解消し、より効率的かつ高品質な開発プロセスを構築する実践的な方法を解説しました。この連携は、単なるツールの組み合わせにとどまらず、開発文化そのものを変革する可能性を秘めています。
Claude Code × GitHub連携がもたらすビジネスインパクト
Claude CodeとGitHubの連携は、エンジニアリングチームだけでなく、ビジネス全体に多大なインパクトを与えます。
ビジネスインパクトの主なメリットは以下の通りです。
ビジネスインパクトの主なメリット
- 開発期間の短縮とコスト削減: AIによるコード生成と自動化されたCI/CDにより、開発サイクルが大幅に短縮され、市場投入までの時間が加速します。これは、開発コストの削減に直結し、リソースをより戦略的な活動に再配分できます。
- 品質向上とバグの削減: 厳格なコードレビュー、自動テスト、リンティングのパイプライン化により、コードの品質と信頼性が向上します。バグの早期発見と修正は、長期的な保守運用コストの削減に貢献します。
- 市場投入の迅速化: 開発プロセスの効率化により、新しいAIモデルや機能のプロトタイピングからデプロイまでを迅速に行えます。これにより、競合優位性を確立し、市場のニーズに素早く対応できます。
- エンジニアリングチームの生産性向上とイノベーションの促進: エンジニアは、定型的なコーディング作業やデバッグ作業から解放され、より創造的な設計、複雑な問題解決、新しいアルゴリズムの研究開発といった、付加価値の高い業務に集中できます。これは、チーム全体のモチベーション向上とイノベーションの促進に繋がります。
- 技術的負債の軽減: AIによるリファクタリング支援やコーディング規約の自動チェックにより、技術的負債(将来的なメンテナンスコストとなるコード品質の悪化)の蓄積を抑制し、健全なコードベースを維持できます。
これらのビジネスインパクトは、企業がAI技術を競争力の源泉として最大限に活用するための強力な基盤となります。
導入におけるQ&Aとトラブルシューティングのヒント
新たなツールの導入には、少なからず課題が伴います。ここでは、Claude CodeとGitHub連携の導入時によくある質問と、その解決策のヒントを示します。
導入時のQ&Aとトラブルシューティングについて解説します。
導入時のQ&Aとトラブルシューティング
- Q: Claude Codeが期待通りのコードを生成してくれません。どうすれば良いですか?
- A: プロンプトエンジニアリングを改善してください。より具体的で詳細な要件、出力形式の指定、制約条件の追加、Few-shot Promptingの活用を試みてください。必要に応じて、タスクを小さなステップに分割し、段階的に指示を与えてみましょう。
- Q: AI生成コードの品質レビューに時間がかかります。効率化のヒントはありますか?
- A: CI/CDパイプラインにリンターや静的解析ツールを組み込み、基本的な品質チェックを自動化しましょう。レビューアは、より高度なロジック、設計、セキュリティの側面、そして要件との整合性に集中できるようになります。また、AI生成コードは「提案」として捉え、完璧を求めすぎずに、必要に応じて人間が修正を加える柔軟な姿勢も重要です。
- Q: GitHub Actionsの設定が複雑で、うまく動作しません。
- A: 公式ドキュメントや豊富なコミュニティのサンプルを参照してください。最初は簡単なワークフローから始め、徐々に複雑なステップを追加していくのが良いでしょう。YAMLファイルの構文エラーは非常によくある原因なので、構文チェッカーの利用も推奨します。
- Q: 機密情報をClaude Codeに渡すのが不安です。安全な利用方法は?
- A: APIキーは環境変数やGitHub Secretsで厳重に管理し、コードに直接記述しないことを徹底してください。機密性の高いコードやデータは、可能な限り匿名化・抽象化してからAIに入力するか、入力自体を避けることを検討してください。Anthropic社のデータ利用ポリシーを十分に理解し、社内コンプライアンスチームと連携することも重要です。
- Q: AI生成コードによる技術的負債が心配です。
- A: 定期的なコードレビューとCI/CDによる品質チェックを徹底することが最も重要です。また、AI生成コードを盲目的に受け入れるのではなく、常にその意図と品質を人間が評価し、必要に応じてリファクタリングや改善を行うサイクルを確立すべきです。
これらのヒントを活用し、試行錯誤を繰り返しながら、チームに最適なAI開発フローを確立すべきです。
今後の展望とさらなる効率化への道
Claude CodeとGitHub連携は、AI開発の未来を形作る重要な一歩ですが、その可能性は今後も広がり続けます。
AIと人間の協調による開発、すなわち「Human-in-the-Loop」は、これからの開発パラダイムの主流となる見込みです。AIがルーティン作業や初期のコード生成を担当し、人間が創造的な問題解決、戦略的な設計、そしてAIの出力の最終的な品質保証に集中することで、開発プロセス全体の効率と品質を最大化できます。この協調は、人間のエンジニアのスキルを陳腐化させるものではなく、むしろ彼らがより高度で魅力的な業務にシフトするための強力なツールとなるはずです。
大規模言語モデル(LLM)は日々進化しており、より高度な推論能力、マルチモーダル対応、そして長文コンテキストの処理能力を獲得しています。これにより、将来的には、さらに複雑なシステム設計、アーキテクチャ提案、あるいはプロジェクトマネジメントの一部までをAIが支援する可能性を秘めています。
企業としては、この変化の波に乗り遅れないよう、継続的な学習とツールのアップデートへの対応が不可欠です。新しいAIモデルやGitHub Actionsの機能がリリースされるたびに、その活用方法を模索し、既存のワークフローに組み込む柔軟性を持つことが、未来のAI開発をリードするチームとなるための鍵となります。
Claude CodeとGitHubを駆使し、皆様のAI開発が次のレベルへと飛躍することを期待しています。