
目次
本記事のポイント
- 生成AIの活用において、データ品質はAIモデルの性能やビジネス成果を大きく左右する重要な基盤であることを理解できます。
- データ品質を構成する「正確性」「完全性」「一貫性」「適時性」「関連性」といった5つの要素とその重要性が明確になります。
- データ品質が低い場合に生じるAIの誤学習、顧客からの信頼喪失、無駄なコストといった具体的なリスクを把握できます。
- 生成AI時代におけるデータ品質管理の新たな課題、特に「意味の理解」や「AIモデルの透明性」への貢献について理解が深まります。
- データ品質評価のポイント、データクレンジングツール、ガバナンス体制構築など、今日から始められる具体的なアクションステップがわかります。
生成AIの力を最大限に引き出す鍵:データ品質管理入門
近年、生成AIは私たちのビジネスに大きな変革をもたらし、その応用範囲は文章生成、画像生成、コード記述など広がり続けています。業務効率化や新たな価値創造の可能性を秘めている一方で、この強力なテクノロジーを最大限に活用するには、ビジネスの根幹を支える「データ品質」が不可欠です。
皆さんは日々、AIモデルの構築やデータ分析に携わる中で、データの取り扱いに多大な時間を費やしていることでしょう。本記事では、生成AI時代におけるデータ品質管理の重要性はもちろん、その基本的な考え方から実践的なアプローチまでを、技術担当者の皆様に向けてやさしく解説します。
なぜ今、データ品質がそんなに大切なのでしょうか?
生成AIは、大量のデータからパターンを学習し、新たなコンテンツを生み出します。この「学習」の質が最終的な生成物の品質を大きく左右するため、もし学習データに問題があれば、AIは誤った学習をし、期待外れな結果やビジネスに悪影響を及ぼす出力につながる可能性があります。
生成AIがもたらすビジネス変革と、その裏側
生成AIは、RPAと連携した自動応答システム、マーケティングコンテンツの自動生成、開発におけるコードアシスタントなど、すでに多くの企業で導入され始めています。例えば、顧客からの問い合わせに最適な回答を瞬時に生成するチャットボットは、顧客体験を向上させ、オペレーターの負担を軽減する実例です。
しかし、もしFAQデータに古い情報や誤った情報が含まれていたらどうなるでしょうか。チャットボットは顧客に間違った情報を伝え、混乱を招いたり、企業への不信感につながったりするかもしれません。これは生成AIが「質の低いデータ」から学習した結果、誤った出力を生成してしまった典型的なケースです。生成AIが賢ければ賢いほど、その賢さの源泉であるデータの品質が問われることになります。
「とりあえずデータがあればOK」はもう通用しない?
一昔前までは、「まずはとにかくデータを集めよう」「データ量があればなんとかなる」といった考え方も主流でした。確かに、データ量が少なすぎる場合は十分な学習ができませんが、生成AI時代においては、ただデータ量が多いだけでは不十分です。
量に加え、データの質が決定的な意味を持つようになりました。生成AIは人間が教えたデータに忠実に学習し、出力するため、もしデータの中に偏りや誤り、矛盾が多く含まれていれば、AIもそれらを学習し、偏った、誤った、あるいは矛盾した結果を出力してしまいます。これを「ゴミを入れたらゴミが出てくる(Garbage In, Garbage Out:GIGO)」と表現することもあります。現代のビジネス環境では、データに基づいた意思決定やAIによる高度な自動化が当たり前になりつつあり、この流れの中で「とりあえずデータがあればいい」という姿勢は、ビジネスにおける大きなリスクとなり得ます。
そもそも「データ品質」って何だろう?基本のキホン
データ品質という言葉を耳にしても、具体的に何を指すのか漠然としている方もいらっしゃるかもしれません。ここでは、データ品質の基本的な概念と、その重要性について深掘りしていきます。
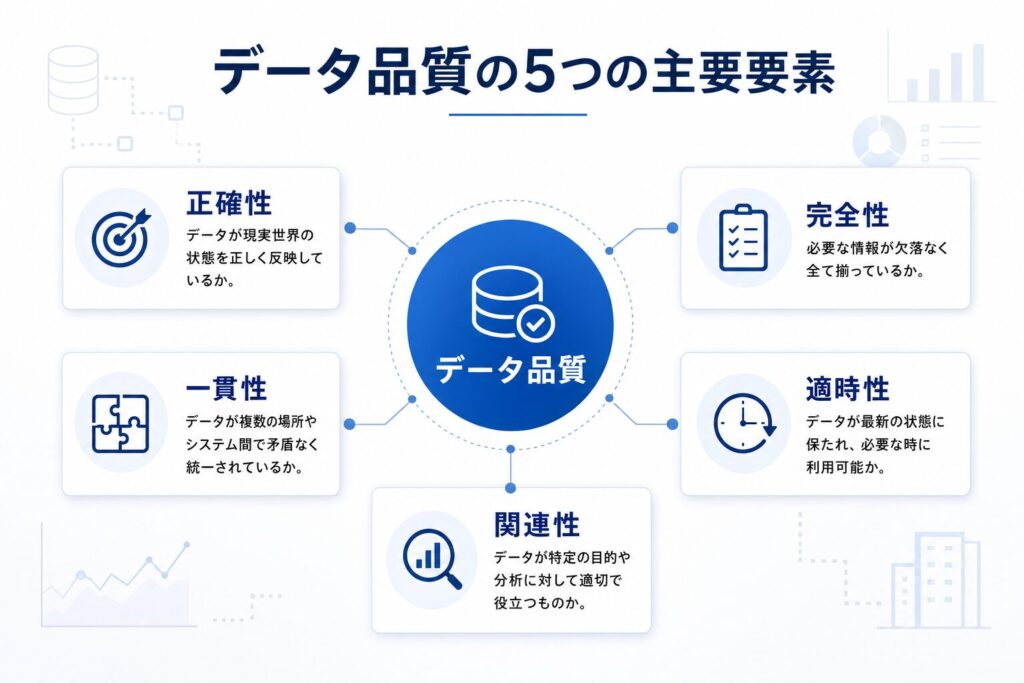
データ品質を構成する5つの要素とは?(正確性、完全性、一貫性、適時性、関連性)
データ品質は、いくつかの要素の組み合わせによって評価されます。これらの要素を理解することで、ご自身の担当するデータのどこに改善の余地があるのか、具体的に見えてくるはずです。
データ品質を構成する5つの主要要素
- 正確性(Accuracy): データが現実世界の状態を正しく反映しているか。例:顧客の住所が実際に存在する正しい番地か。
- 完全性(Completeness): 必要な情報が欠落なく全て揃っているか。例:顧客の電話番号やメールアドレスが全て入力されているか。
- 一貫性(Consistency): データが複数の場所やシステム間で矛盾なく統一されているか。例:同じ顧客名でも、別のシステムで表記揺れがないか。
- 適時性(Timeliness): データが最新の状態に保たれ、必要な時に利用可能か。例:在庫情報がリアルタイムで更新されているか。
- 関連性(Relevance): データが特定の目的や分析に対して適切で役立つものか。例:営業戦略に必要な情報が十分に収集されているか。
これらの要素は相互に関連しており、どれか一つが欠けてもデータ品質は低いと評価されてしまいます。例えば、顧客の連絡先データが正確でも完全でなければ、マーケティングキャンペーンに活用できない可能性があります。また、適時性が失われた古いデータは、たとえ正確であっても関連性が低く、現在のビジネス判断には役立ちません。
「良いデータ」と「悪いデータ」がビジネスにもたらす違い
では、これらの要素が満たされた「良いデータ」と、そうでない「悪いデータ」が、実際のビジネスにどのような影響を与えるのでしょうか。データは単なる情報ではなく、ビジネスを動かす「燃料」であり「羅針盤」です。その燃料の品質が悪ければエンジンはうまく動かず、羅針盤が間違っていれば目的地にはたどり着けません。
良いデータがもたらすもの:
- 信頼性の高いAIモデル: 正確で完全なデータは、AIがより賢く、的確な予測や生成を行う基盤を築きます。
- 迅速で正確な意思決定: 最新かつ一貫性のあるデータは、経営層や現場が客観的な根拠に基づき、迷いなく意思決定を下せるよう支援します。
- 顧客満足度の向上: パーソナライズされたサービスや正確な情報提供が可能となり、顧客からの信頼を獲得できます。
- 効率的な業務運営: データの探索や修正にかかる無駄な時間が減り、従業員はより価値の高い業務に集中できるようになります。
悪いデータがもたらすもの:
- AIモデルの性能低下: 誤ったデータや偏りのあるデータは、AIが誤った学習をし、不正確な結果や偏った出力を生み出す原因となります。
- 間違った意思決定: 古いデータや矛盾したデータに基づいた判断は、ビジネスチャンスを逃したり、逆にリスクを招いたりする可能性があります。
- 顧客からの信頼喪失: 不正確な情報提供や誤ったパーソナライゼーションは、顧客の不満や企業のブランドイメージ低下につながります。
- 無駄なコストと時間の発生: データの修正作業、不正確な分析による再検証、無駄なキャンペーン実施など、目に見えないコストが増大します。
この違いをしっかりと認識することが、データ品質管理への第一歩となります。
データ品質が低いと、どんな困ったことが起こる?
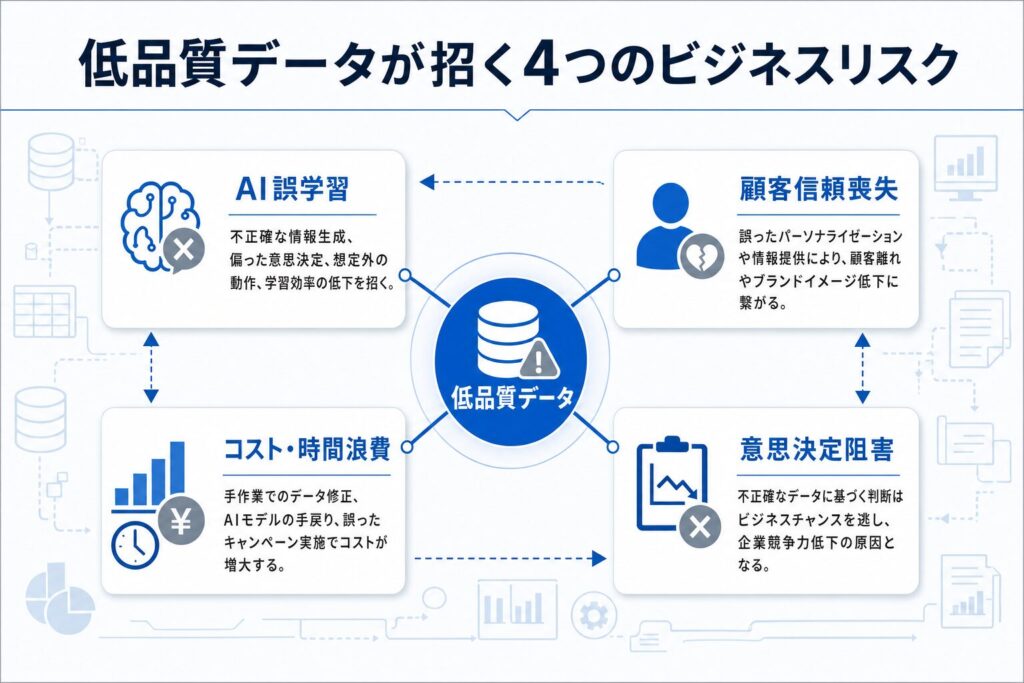
データ品質がビジネスに与える悪影響は様々です。ここでは、具体的な困りごとやリスクについて見ていきましょう。
AIが「間違った学習」をしてしまう現実
生成AIは、学習したデータから世界のパターンを認識します。もし学習データに誤った情報や偏った情報が含まれていれば、AIもその誤りや偏りをそのまま吸収してしまうでしょう。
例えば、顧客対応チャットボットに古い製品情報が混ざったデータを学習させると、チャットボットは最新の製品ではなく、販売終了した製品について語り始めるかもしれません。また、特定の性別や人種に対する偏見を含んだテキストデータを学習させると、AIが差別的な表現を生成してしまう「AIバイアス」の問題も発生し得ます。これは、AIの公平性や倫理性が問われる非常に深刻な問題です。
AIの「間違った学習」が引き起こす問題
- 不正確な情報の生成: 古いデータや誤ったデータに基づき、事実とは異なる内容を出力します。
- 偏った意思決定: 訓練データに含まれる社会的な偏見を学習し、公平性を欠いた判断や提案を行います。
- 想定外の動作: エラーデータが混入することで、AIモデルが意図しない挙動を示し、システム障害や誤作動を引き起こします。
- 学習効率の低下: ノイズや重複が多いデータは、AIの学習を妨げ、モデルの収束を遅らせる原因となります。
これらの問題は、AIシステム全体の信頼性を損ない、導入のメリットを打ち消す結果につながりかねません。開発や運用に携わる技術担当者として、こうしたリスクを未然に防ぐ責任があります。
顧客からの信頼を失いかねないリスク
企業にとって、顧客からの信頼は何よりも大切な資産です。データ品質の低さは、この信頼を容易に損ねてしまいます。
例えば、顧客の購買履歴データが不正確であれば、AIが推奨する商品が全く見当違いなものになったり、すでに購入済みの商品を再び勧めたりするかもしれません。これは顧客に不快感を与え、企業への評価を下げてしまうでしょう。また、CRMシステム内の顧客情報に誤りがあり、誤った名前でダイレクトメールを送ったり、過去に解約した顧客にまでプロモーションを行ったりするケースも考えられます。
このような体験は、「この会社は顧客のことを理解していない」「個人情報の管理がずさんだ」という印象を与え、最終的には顧客離れにつながってしまいます。特に生成AIを活用したパーソナライゼーションが普及する現代において、データの不正確さは致命的なダメージを与えかねません。
無駄なコストと時間が発生するワケ
データ品質の低さは、目に見えないコストとして企業に重くのしかかります。不正確なデータや欠損データは、データ分析やレポート作成の前に「手作業での修正」を必要とし、これは膨大な時間と人件費を浪費することになります。
例えば、複数のシステムに散らばった顧客データで表記揺れがある場合、それぞれのシステムで手作業で統一作業を行うのは非常に非効率です。また、AIモデルの精度が低い場合、その原因を特定し、データを再収集・再加工してモデルを再学習させるという「手戻り」が発生し、開発期間を大幅に延長させ、予期せぬコスト増を招きます。さらに、誤ったデータに基づくマーケティングキャンペーンは効果が出ずに広告費を無駄にすることもあり、結局担当者がExcelで手作業で集計・加工し直すという、RPAやAIを導入した意味がない状況に陥ることも少なくありません。
データドリブンな意思決定ができないもどかしさ
データドリブンな意思決定とは、勘や経験に頼るのではなく、客観的なデータに基づいて戦略を立て、ビジネスを推進していくことです。しかし、データ品質が低いと、このデータドリブンなアプローチが機能しなくなります。
もし分析レポートの元データが不正確であれば、そのレポートから導き出される結論もまた不正確なものとなります。経営層はどのデータを信じて良いか分からず、結局は経験則や主観に頼った意思決定に戻ってしまうかもしれません。これでは、AIやデータ基盤への投資が無駄になってしまいます。例えば、市場トレンド分析のために収集したSNSデータにノイズが多く、実際のトレンドとは異なる結果が出た場合、この誤った分析結果に基づいて新製品を開発すれば、市場のニーズとミスマッチを起こし、大きな損失につながる恐れがあるでしょう。データが信用できないという状況は、ビジネス成長の足かせとなり、企業競争力低下の直接的な原因となります。
データ品質が良いと、どんな良いことがある?
データ品質が低いと様々な問題が生じる一方で、データ品質が良いことには多くのメリットをもたらします。ここからは、良いデータがもたらすポジティブな効果について見ていきましょう。
信頼できるAIが「賢い提案」をしてくれる
質の高いデータは、AIモデルが現実世界を正確に理解し、より賢明な判断や提案を行うための基盤を築きます。生成AIが質の良いデータから学習すれば、その出力もまた信頼性の高いものとなるでしょう。
例えば、顧客の最新かつ正確な購買履歴や行動履歴、興味関心を示すデータが豊富に揃っていれば、AIはそれぞれの顧客に最適化された商品を提案したり、次に購入しそうな商品を予測したりできるようになります。これにより、顧客は本当に求めている情報や商品に出会うことができ、企業は効率的に売上を向上させることが可能です。また、社内向けに文書を生成するAIであれば、企業の最新の公式情報や規定に基づいた、正確で一貫性のある文書を作成できるため、社員の業務効率も大きく向上するでしょう。
迅速で正確な意思決定が可能になる
良質なデータは、経営層から現場の担当者まで、あらゆる階層の意思決定を支援します。データが正確で、かつ最新の状態に保たれていれば、意思決定者は迷うことなく、迅速かつ自信を持って判断を下すことができます。
例えば、市場動向を分析する際、リアルタイムで更新される信頼性の高いデータがあれば、競合他社に先駆けて新しい戦略を打ち出したり、リスクを早期に察知して回避策を講じたりすることが可能になります。また、製造業であれば、センサーデータから製品の品質低下の兆候を早期に捉え、迅速に生産ラインの調整を行うことで、不良品の発生を最小限に抑えることができるでしょう。データが「真実」を語るため、客観的な根拠に基づいた意思決定が日常的に行われるようになります。
顧客満足度とビジネス成果への貢献
良いデータは顧客への理解を深め、パーソナライズされた体験を提供することを可能にします。これにより顧客満足度は大きく向上し、ロイヤルティの強化につながります。
データ品質が顧客満足度とビジネス成果に貢献する例
- パーソナライズされた体験: 顧客の正確なデータに基づき、興味関心に合致した商品やサービスをタイムリーに提案し、エンゲージメントを高めます。
- 迅速な問題解決: 顧客からの問い合わせに対し、正確な履歴データや製品情報を用いて素早く的確な回答を提供し、ストレスを軽減します。
- 効率的なマーケティング: ターゲット顧客に最適化されたメッセージを届けることで、広告の費用対効果が向上し、見込み顧客獲得率が高まります。
- 新製品開発の最適化: 顧客の声や市場トレンドを正確に分析し、真にニーズのある製品・サービス開発につなげ、市場投入後の成功率を高めます。
これらの結果として、顧客離反率の低下、アップセル・クロスセルの増加、新規顧客獲得の効率化といった具体的なビジネス成果に直結します。つまり、データ品質は単なる技術的な課題ではなく、企業の競争力そのものに影響を与える戦略的な要素なのです。
従業員の生産性向上と業務効率化
データ品質の向上は、従業員の働き方にも良い影響をもたらします。データが整理され、信頼できる状態であれば、データの探索や修正にかかる時間は大幅に削減されるでしょう。
例えば、営業担当者が顧客情報を参照する際に、最新の情報が常に正確に表示されていれば、顧客への提案準備にかかる時間を短縮できます。データ入力担当者も、重複データや誤入力のチェック作業に追われることが減り、本来の業務に集中できるようになります。また、データサイエンティストやアナリストも、データクレンジングに費やす時間を減らし、より高度な分析やモデル構築といった付加価値の高い業務に時間を割けるようになるでしょう。
このように、データ品質の向上は、組織全体の生産性を底上げし、従業員がより創造的で戦略的な仕事に取り組める環境を整備する上で不可欠な要素です。
生成AI時代のデータ品質管理、何が変わるの?
生成AIの登場は、データ品質管理に新たな視点と課題をもたらしました。単に「データが正しいか」だけでなく、「データが意味をなすか」という、より深い問いが加わったと言えるでしょう。
大量データの活用が新たな課題を生む
生成AIは、従来のAIモデルと比較して、はるかに大量のデータを学習する必要があります。インターネット上の膨大なテキスト、画像、音声データなどを取り込み、その中から複雑なパターンや文脈を理解しようとします。
この「大量データ」が新たな課題を生みます。データソースが多岐にわたるため、異なる形式のデータを統合する際の課題や、各データソースの信頼性を評価する難しさが増すでしょう。また、人間が一つ一つ手作業で全てのデータの内容をチェックすることは現実的に不可能です。そのため、データの収集段階から品質を担保する仕組みや、自動的に異常を検知する技術がこれまで以上に求められます。単に「データがある」だけではなく、「信頼できる質の高い大量データ」が不可欠なのです。
「意味の理解」が問われるAI時代のデータ品質
従来のデータ品質管理では、データの「形式」や「整合性」に焦点が当てられることが一般的でした。例えば、数値データが正しく数値として入力されているか、日付形式が統一されているか、といった点です。
しかし生成AIにおいては、データが持つ「意味」や「文脈」の品質が極めて重要になります。例えば、過去の顧客対応履歴を学習させる場合、単にテキストデータがあるだけでなく、それがどのような状況でのやり取りであったのか、感情的なニュアンスはどうか、といった「意味」がAIの出力に大きく影響します。もし、誤解を招くような表現や偏った意見ばかりのデータが混ざっていれば、AIも同様の傾向を示す可能性があります。
「意味の理解」が問われるデータ品質の例
- テキストデータ: 特定のキーワードが、文脈によって肯定的な意味にも否定的な意味にもなり得る点をAIが正確に理解できるか。
- 画像データ: 画像に写る物体の認識だけでなく、その画像の意図や感情的な背景をAIが汲み取れるか。
- 音声データ: 発話の内容だけでなく、話者の感情や抑揚がAIに正しく伝わり、適切な返答を生成できるか。
- コードデータ: 単に構文が正しいだけでなく、そのコードが実現しようとしている機能や目的をAIが理解しているか。
生成AIは「意味」を生成するため、「意味」の品質管理が不可欠です。データ自体が持つ意味的な正確さ、中立性、多様性などが、これからのデータ品質管理の新たな重要課題となります。
人間が気付かないエラーもAIが見つけ出す可能性
皮肉なことに、生成AIはデータ品質管理の課題を提起する一方で、その解決策の一部となる可能性も秘めています。大量のデータの中から人間では見逃してしまうような複雑なパターンや異常を、AIが検出できるケースが出てきているのです。
例えば、自然言語処理(NLP)を活用したAIモデルは、テキストデータ内の矛盾、表記揺れ、特定の意図しない偏りなどを自動で識別し、品質改善のヒントを提供できます。また、画像データであれば、目視では区別しにくい微細な欠陥や、意図しない被写体の混入などをAIが検知することも可能です。これにより、データ品質管理のプロセスを自動化・効率化し、人間はより高度な判断や戦略的な業務に集中できるようになるかもしれません。AIを品質管理の「パートナー」として活用する視点が、今後ますます重要になります。
AIモデルの「透明性」と「説明責任」を支える品質
生成AIモデルが複雑化するにつれて、「なぜAIがその答えを出したのか」「どのような基準で判断したのか」といった透明性(Interpretability)と説明責任(Accountability)の重要性が増しています。特に、医療診断や金融取引のような高リスクな領域では、AIの判断根拠を明確に示せなければ、社会的な受容は得られません。
この透明性と説明責任を支える根幹が、データの品質です。高品質なデータで学習されたAIは、その学習過程や出力結果の根拠をより明確に説明しやすくなります。逆に、質の低い、あるいは偏りのあるデータで学習されたAIは、その出力結果の信頼性が揺らぎ、説明責任を果たすことが困難になるでしょう。例えば、採用活動にAIを活用する場合、特定の属性を持つ候補者ばかりを推奨するAIが問題視されることがありますが、この場合、学習データに過去の採用実績の偏りが反映されている可能性が高いです。データの品質を管理し、偏りのないデータでAIを学習させることで、初めて公平で説明可能なAIシステムを構築できるのです。データ品質管理は、AIが社会に受け入れられ、信頼されるための土台作りの役割も担っています。
今日から始める!データ品質管理の第一歩
データ品質管理の重要性をご理解いただけたところで、では実際に何をすれば良いのか、具体的なステップを見ていきましょう。決して壮大なプロジェクトである必要はありません。まずは身近なところから始めることが大切です。
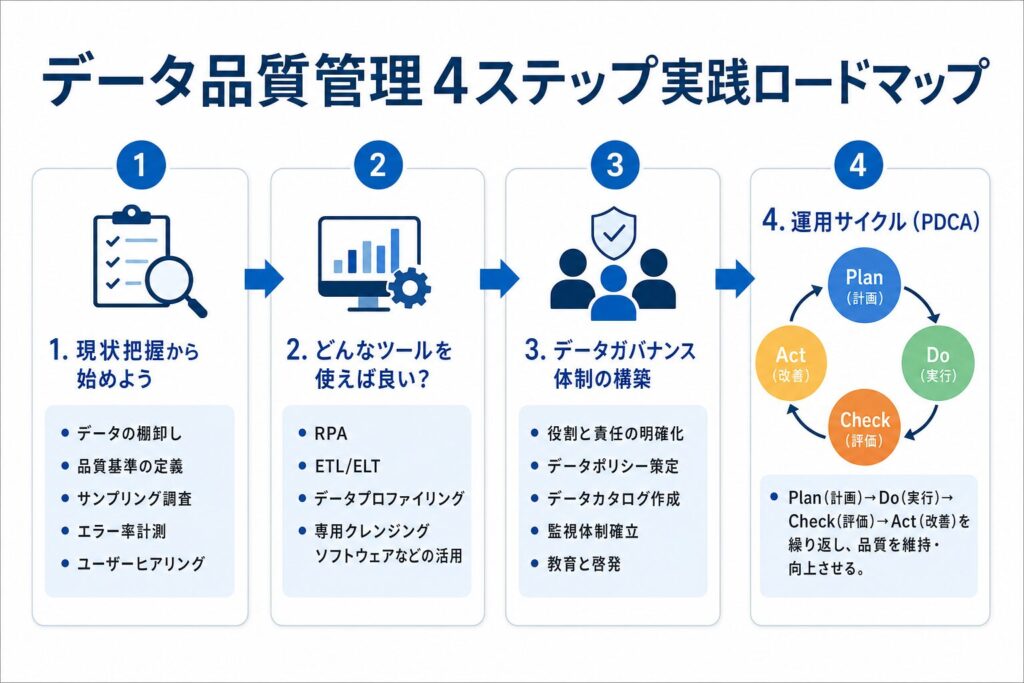
現状把握から始めよう:データ品質評価のポイント
データ品質を改善するためには、まず現状がどうなっているのかを知ることが不可欠です。どこに問題があり、どの程度深刻なのかを評価するポイントをいくつかご紹介します。
データ品質評価の具体的なポイント
- データの棚卸し: どのシステムにどんなデータがあるのか、誰が管理しているのかを洗い出し、全体像を把握します。
- 品質基準の定義: 「正確性」とは何か、「完全性」はどのレベルかなど、組織内で統一された品質基準を具体的に定めます。
- サンプリング調査: 全データを調査するのが難しい場合、一部を抜き出して手作業で品質チェックを行い、傾向を把握します。
- エラー率の計測: 欠損値の割合、重複レコードの数、入力形式の不統一の発生頻度などを具体的な数値で計測します。
- ユーザーヒアリング: 実際にデータを使っている現場の担当者から、困っていることや「使えないデータ」の実態をヒアリングします。
これらの評価を通じて、まずは「最も問題が深刻で、かつ改善効果が大きいと考えられるデータ」から着手することをおすすめします。全てを一度に完璧にしようとすると、途中で挫折してしまう可能性もありますから、スモールスタートで始めるのが成功の秘訣です。
どんなツールを使えば良い?具体的な選択肢
データ品質管理を効率的に進めるためには、適切なツールの活用が不可欠です。手作業での対応には限界がありますので、ぜひ導入を検討してみてください。
データクレンジング・正規化ツールの活用
データクレンジングとは、データ内の誤りや不整合を取り除き、きれいな状態にすることを指します。正規化は、データの形式や表記を統一する作業であり、これらの作業を自動化・半自動化してくれるツールは、技術担当者の強い味方となります。
データクレンジング・正規化ツールの種類と機能例
- RPAツール: 定型的なデータ入力ミス修正、特定形式への変換、重複データ検知・削除など、ルールベースの処理を自動化します。
*例: UiPath, Blue Prism, Power Automate など*
- ETL/ELTツール: 異なるシステムからのデータ抽出(Extract)、変換(Transform)、ロード(Load)を行う際に、品質チェックやデータ整形を組み込めます。
*例: Informatica, Talend, Azure Data Factory など*
- データプロファイリングツール: データの統計情報(最大値、最小値、平均、欠損率など)を分析し、異常値や不整合を可視化します。
*例: Ataccama ONE, Collibra Data Quality など*
- 専用のデータクレンジングソフトウェア: 住所の正規化、氏名表記の統一、電話番号のフォーマット修正など、特定のデータ型に特化した高精度なクレンジング機能を提供します。
*例: Trillium Software, DataLadder など*
これらのツールを導入することで、データクレンジングにかかる時間と労力を大幅に削減し、より信頼性の高いデータをAIモデルの学習や分析に利用できるようになります。自社のデータ量、種類、予算に応じて最適なツールを選択しましょう。
データガバナンス体制の構築
ツール導入と並行して、組織全体でデータを適切に管理・運用するための「データガバナンス」体制を構築することも重要です。これは、単に技術的な問題だけでなく、組織の文化やプロセスに関わる課題です。
データガバナンス体制構築のポイント
- 役割と責任の明確化: 誰がどのデータのオーナーで、品質に対して責任を持つのかを明確にします。
- データポリシーの策定: データ収集、保管、利用、廃棄に関するルールや基準を文書化し、組織全体で共有します。
- データカタログの作成: どのシステムにどのようなデータがあるか、メタデータ(データの定義や出所など)を一元管理するデータベースを作成します。
- 品質基準と監視体制の確立: 定期的にデータ品質を評価し、基準から逸脱した場合にアラートを発する仕組みを導入します。
- 教育と啓発: 従業員に対し、データ品質の重要性や適切なデータ取り扱い方法について定期的な研修を実施します。
データガバナンスは、一時的なプロジェクトではなく、継続的な取り組みです。組織全体でデータ品質への意識を高め、協力体制を築くことが成功の鍵となります。
データ品質を維持するための運用サイクル
データ品質は一度改善すれば終わり、というものではありません。ビジネス環境の変化や新しいデータの流入によって、品質は常に変動する可能性があります。そのため、継続的な運用サイクルを確立することが重要です。
これは一般的に「PDCAサイクル」として知られる考え方をデータ品質管理に応用するものです。
- Plan(計画): どのようなデータを、どのレベルの品質で管理するかを計画します。品質基準の定義や目標設定が含まれます。
- Do(実行): 計画に基づき、データの収集、クレンジング、統合、保管などの作業を実行します。ツールや体制を最大限に活用します。
- Check(評価): 定期的にデータ品質を評価し、計画通りの品質が維持されているか、目標が達成されているかをチェックします。
- Act(改善): 評価の結果、問題点が見つかった場合は、原因を特定し、改善策を講じて次の計画に反映させます。
このサイクルを回し続けることで、常に変化するビジネスニーズに対応し、データ品質を高いレベルで維持し続けることが可能になります。特に、生成AIのような新しい技術が導入される際には、データ品質の要件も変化する可能性があるため、このサイクルを柔軟に調整していく姿勢が求められます。
まとめ:生成AI時代を勝ち抜くためのデータ品質管理
生成AIは、私たちのビジネスに革命的な変化をもたらす大きな可能性を秘めた強力なツールです。しかし、その真価を発揮させるためには、AIの根幹を支える「データ」の品質が何よりも重要であることを、ここまでお伝えしました。
データはビジネスの「血液」です
企業におけるデータは、まさに人間の体における血液のようなものです。血液の質が悪ければ体調を崩すように、データの質が悪ければビジネスは健全に機能しません。特に、生成AIが企業戦略の重要な一部となりつつある今、データ品質は単なるバックオフィス業務ではなく、企業の競争力と信頼性を左右する戦略的な資産として捉えるべきです。
質の良いデータは、信頼性の高いAIモデルを生み出し、迅速で正確な意思決定を促し、結果として顧客満足度とビジネス成果の向上に貢献します。一方で、質の低いデータは、AIの誤学習や顧客からの信頼喪失、無駄なコストといった様々なリスクを招いてしまうでしょう。
今こそデータ品質管理を見直しませんか?
技術担当者である皆さんは、日々データと向き合い、AIやRPAシステムを構築・運用されています。だからこそ、データの品質がどれほど重要か、身をもって感じていらっしゃるかもしれません。
生成AI時代のデータ品質管理は、単なるデータの整合性チェックに留まらず、データが持つ「意味」や「文脈」まで含めた深い理解が求められます。それは、AIモデルの透明性と説明責任を支え、最終的にはAIが社会に受け入れられるための基盤となるでしょう。
今日からできる小さな一歩から始めましょう。まずは現状のデータ品質を評価し、データクレンジングツールの導入を検討したり、部署内でのデータ管理ルールを見直したりするだけでも、大きな変化につながります。データ品質管理は一朝一夕で完了するものではありませんが、継続的な取り組みによって、必ずや生成AIの力を最大限に引き出し、貴社のビジネス成長を加速させる強力な武器となるはずです。この機会に、貴社のデータ品質管理を見直し、より賢く、より信頼できるAIシステムを構築するための一歩を踏み出してみてはいかがでしょうか。