
目次
- なぜあなたのAIプロジェクトは期待外れに終わるのか?データという盲点
- そのAI、データが原因で「使えない」と烙印を押される3つの落とし穴
- 【落とし穴1】「質の低いデータ」がAIの判断を狂わせる実務現場の悲劇
- 不正確・欠損データが導く「間違った予測」とビジネス機会の損失
- 現場担当者が語る、データ入力規則の不徹底がプロジェクトを破綻させる事例
- 【落とし穴2】「偏った・不足したデータ」がAIのポテンシャルを殺す
- 限られた学習データでは「特定の業務でしか使えないAI」になる
- 現実と乖離したデータが、現場に「これじゃ使い物にならない」と言われる原因
- 【落とし穴3】データ準備への「甘い認識」が予算と時間を溶かす泥沼
- AI導入「前」に潜む、データクレンジング・前処理の「見えない工数」
- 教師データ作成(アノテーション)の専門性と、見積もり以上の高コスト
- 失敗から学ぶ:AIプロジェクトを成功に導く「データ戦略」と経営層の役割
- まとめ:データ中心のアプローチこそ、AI投資を成功させる唯一の道
本記事のポイント
- 多くのAIプロジェクトが期待外れに終わる理由は、AIそのものの問題ではなく、「データ」という経営層が見落としがちな盲点にあります。
- AIが現場で「使えない」と烙印を押されるのは、データの質、偏り、不足、そしてデータ準備への甘い認識という3つの落とし穴が原因です。
- 不正確なデータはAIを誤った判断に導き、不十分なデータはAIの汎用性を著しく低下させ、結果的にビジネス機会の損失や投資の無駄遣いを招きます。
- AIプロジェクト成功には、着手前の「現状データ評価」、現場を巻き込んだ「データ整備・収集体制」の確立、そして「データガバナンスの構築」が不可欠です。
- 経営層は、AI投資を成功させるために、データに対する認識を改め、データ中心のアプローチを戦略的に推進することが求められます。
なぜあなたのAIプロジェクトは期待外れに終わるのか?データという盲点
AI技術は、企業の競争力強化、業務効率化、新たな価値創造の切り札として、多くの経営者や管理職の皆様から高い期待が寄せられています。しかし、その期待とは裏腹に、AIプロジェクトの失敗談が後を絶ちません。
「期待外れに終わった」「PoC(概念実証)止まりで本格導入に至らない」「現場で全く使われない」といった声も多く聞かれます。このような状況に直面し、「AIは本当に効果があるのか?」といった疑問を抱く方も少なくないでしょう。
しかし、問題はAIそのものの性能や技術的な複雑さにあるのではありません。多くの場合、企業がAIの「燃料」となるデータについて、その本質的な重要性を見落としている点に根本的な原因があるのです。この「データ」という盲点こそが、AIプロジェクトの成否を分ける決定的な要因となります。
投資したのに成果が出ない…AIプロジェクトが抱える「沈黙の失敗」とは
「数千万円を投資したはずなのに、業務はほとんど変わっていない」「導入したAIが、現場の特定の担当者しか使っていない」「プロジェクトの目標が曖昧なまま、時間だけが過ぎていく」。これらは、AIプロジェクトが直面する「沈黙の失敗」の典型的な兆候です。
明確な中止や撤退という形ではなく、じわじわと期待がしぼんでいくような、表面化しにくい失敗と言えるでしょう。このような失敗は、AIプロジェクトの初期段階で描かれた壮大なビジョンや期待と、実際の成果との間に大きな隔たりを生じさせます。
結果として、経営層はAIへの不信感を抱き、現場は新しいテクノロジーへの抵抗感を募らせる事態になりかねません。しかし、この「沈黙の失敗」の根底には、AI技術そのものの問題よりも、「データ」の扱いに起因する根本的な課題が横たわっていることがほとんどです。
経営層が見落としがちな「AIの燃料」=データの決定的な重要性
AIは、学習データに基づいてパターンを認識し、推論や予測を行います。人間が物事を判断する際に経験や知識を必要とするのと同様に、AIも「データ」という名の情報源がなければ、何も学習できず、何も判断できません。
データはAIにとって、まさに「燃料」であり、その知性そのものを形成する基盤なのです。しかし、多くの企業ではAI導入の検討段階で、高性能なAIモデルや最新のアルゴリズム、華やかなUI(ユーザーインターフェース)に目が向きがちです。
データは「既にそこにあるもの」として当然視され、その質、量、収集方法、管理体制といった側面が十分に検討されないままプロジェクトが推進されてしまうケースが散見されます。経営層の皆様は、AIへの投資を検討する際に、AIが何によって動き、何によって賢くなるのか、その本質を深く理解する必要があります。データは単なる情報資産ではなく、AIの性能を左右する最も重要な要素であるという認識を持つことが、AIプロジェクト成功への第一歩となるでしょう。
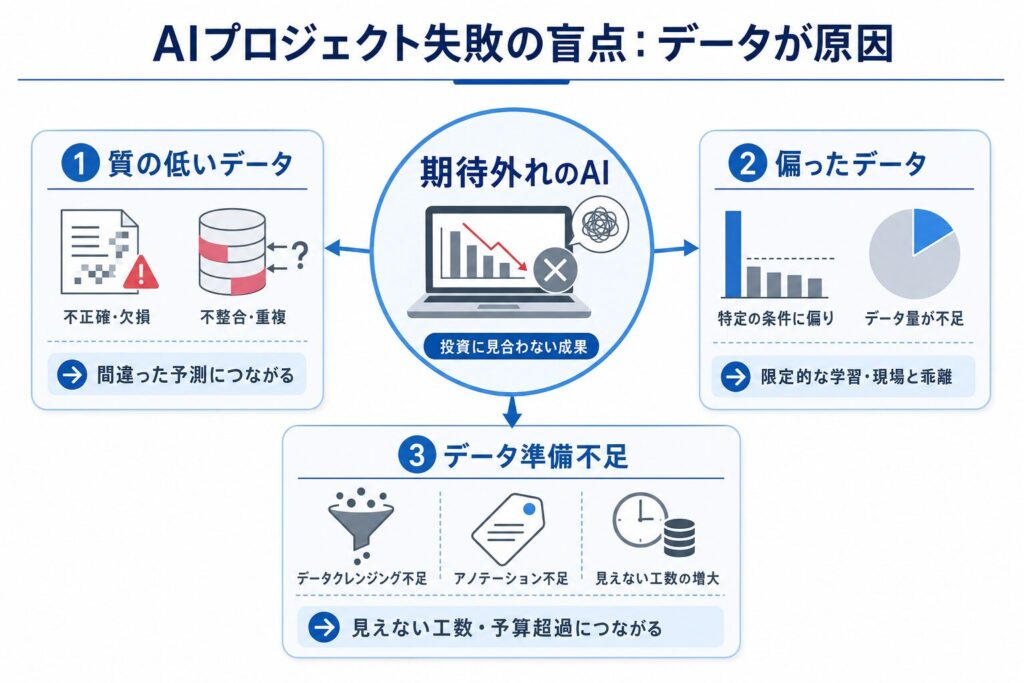
そのAI、データが原因で「使えない」と烙印を押される3つの落とし穴
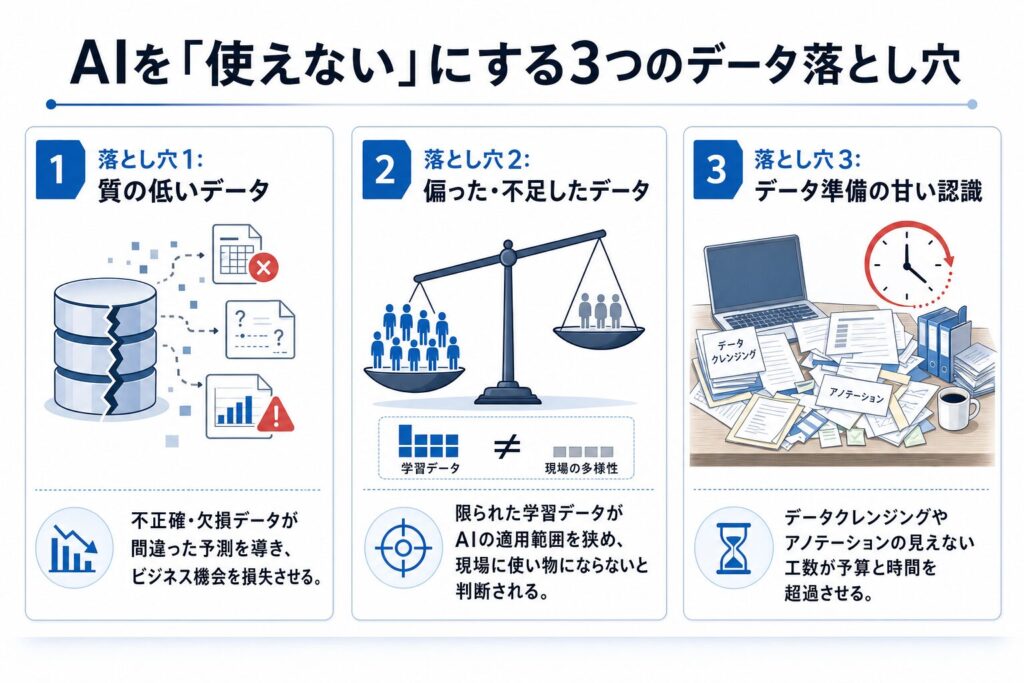
AIが現場で「使えない」と判断される背景には、データの品質や扱い方に関する具体的な課題が潜んでいます。ここでは、AIプロジェクトが陥りやすい3つの「データ」に関する落とし穴について詳しく見ていきましょう。
これらの落とし穴に気づき、対処することで、AI活用の成功に一歩近づけます。
【落とし穴1】「質の低いデータ」がAIの判断を狂わせる実務現場の悲劇
AIは、与えられたデータを忠実に学習します。そのため、学習データに不正確さや欠損、矛盾が含まれていれば、AIはその「誤った情報」を正しいものとして学習し、結果として誤った判断や予測を導き出してしまいます。これは、実務現場での悲劇を招きかねません。
不正確・欠損データが導く「間違った予測」とビジネス機会の損失
顧客情報が古かったり、入力ミスで氏名や住所が間違っていたり、製品の在庫データがリアルタイムで更新されていなかったりすると、どうなるでしょうか。AIがこれらの不正確なデータで学習すれば、顧客への適切なレコメンドはできず、需給予測は外れ、在庫管理は破綻します。
例えば、最新の販売データが欠損している状態で需要予測AIを稼働させると、実際よりも低い需要を予測してしまい、結果的に機会損失につながる可能性があります。また、顧客の購買履歴に重複や誤った情報が含まれていれば、AIは顧客の真のニーズを把握できず、的外れなマーケティング施策にコストを投じてしまうことにもなりかねません。
質の低いデータが引き起こす問題は多岐にわたります。以下に、具体的な例を挙げます。
質の低いデータが引き起こす具体的な問題例
- 顧客セグメンテーションの失敗:顧客データ内の重複や表記ゆれにより、異なる顧客を同一人物として扱ったり、逆に同一人物を複数人として認識したりして、パーソナライズされたアプローチが不可能になる。
- 需要予測の誤差:販売データや在庫データに欠損や遅延があると、AIが市場のトレンドや季節性を正確に学習できず、過剰生産や品切れを引き起こす。
- 不正検知精度の低下:過去の不正事例データが不十分だったり、正常データにノイズが多かったりすると、AIが不正パターンを適切に識別できず、見逃しや誤検知が頻発する。
このような問題は、最終的にビジネス機会の損失や、顧客満足度の低下、企業の信頼性失墜に直結します。質の低いデータは、AIの性能を最大限に引き出すどころか、かえってビジネスに悪影響を及ぼしかねないのです。
現場担当者が語る、データ入力規則の不徹底がプロジェクトを破綻させる事例
質の低いデータが発生する主な原因の一つに、現場でのデータ入力規則の不徹底があります。たとえば、
- 担当者によって日付の形式が「2023/1/1」と「2023-01-01」のように異なる。
- 製品名や顧客名をフリーテキストで入力するため、表記ゆれが多発する(例:「A社」「株式会社A」「A」)。
- 必要な項目が未入力のまま登録されることが常態化している。
このような状況は、複数の部署やシステムにまたがるデータをAIで活用しようとする際に、大きな障壁となります。データ統合の際に膨大な時間と手間がかかるだけでなく、そもそもAIが学習できる状態にまでデータを整形することが困難になるケースも少なくありません。
現場の担当者は、日々の業務に追われる中で、データ入力の重要性を十分に認識していない場合があります。しかし、データ入力のルールが曖昧であったり、徹底されていなかったりすると、どんなに優れたAIモデルを導入しても、その真価を発揮することはできないでしょう。データは入力された時点からその品質が決定されるため、現場のデータ入力精度はAIプロジェクトの成否に直結する重要な要素となります。
【落とし穴2】「偏った・不足したデータ」がAIのポテンシャルを殺す
AIは学習データに存在しない事象やパターンを自ら生み出すことはできません。特定の状況や範囲に偏ったデータ、あるいは絶対的に不足しているデータで学習させたAIは、その学習データの範囲内でしか有効に機能せず、現実の多様なビジネス環境に対応できない「使えないAI」となってしまいます。これは、AIのポテンシャルを大幅に損なう原因です。
限られた学習データでは「特定の業務でしか使えないAI」になる
例えば、ある支店の過去1年間の販売データのみで学習した需要予測AIは、他の地域や長期的なトレンド、季節変動、外部要因による急激な需要変化には対応できません。また、特定の顧客層のデータばかりで学習したレコメンドAIは、それ以外の顧客層には的外れな提案をしてしまうでしょう。
AIは学習したデータの特徴を反映するため、学習データが偏っていれば、AIの判断も偏ります。これにより、AIが特定の業務や状況では役立つものの、それ以外の広範な業務や、当初期待していた汎用的な活用には全く対応できないという事態が発生します。結果として、AIのポテンシャルを十分に引き出すことができず、導入コストに見合う効果を得られなくなってしまうのです。
AIが偏った、または不足したデータで学習すると、以下のような問題が発生します。
AIが偏った・不足したデータで学習するとどうなるか
- 適用範囲の極端な狭さ:特定の製品、地域、顧客層など、学習データに含まれる範囲でしか有効な予測や分類ができないAIとなり、汎用的な業務改善に寄与しない。
- 特定のバイアスの増幅:学習データに人種、性別、年齢などの社会的な偏見が含まれている場合、AIはその偏見を学習し、不公平な判断を下すリスクが生じる(例:採用選考AIでの差別的な判断)。
- 異常値への対応不可:過去に発生していない、あるいは学習データにほとんど含まれていない異常事態やイレギュラーなパターンを認識できず、適切なアラートや対応ができない。
こうしたAIは、導入当初の期待とは裏腹に、現場から「これは特殊なケースに対応できない」「うちの業務には合わない」といった声が上がり、「使えない」という烙印を押されてしまう可能性が高まります。
現実と乖離したデータが、現場に「これじゃ使い物にならない」と言われる原因
ビジネス環境は常に変化しています。過去のデータだけを頼りにAIを学習させると、最新のトレンドや状況変化に対応できないAIができあがってしまいます。
例えば、コロナ禍のような予期せぬ社会情勢の変化や、競合他社の新たな戦略、顧客ニーズの急激な変化など、AIの学習データがこれらの「現実」を反映していなければ、AIの予測や提案は的外れなものとなります。
また、現場で実際に起きている事象と、学習データとして与えられたデータが異なる場合も問題です。製造ラインの異常検知AIが、実際には正常な稼働をしているにも関わらず、過去の特定の条件下で収集されたデータに基づいて「異常」と判断するようなケースです。このようなAIは、現場担当者からすれば「これじゃ使い物にならない」「余計な手間が増えるだけ」と判断され、利用が敬遠される結果となります。AIが現場の現実と乖離していると、信頼を得られず、最終的に誰も使わない形骸化したシステムになってしまうのです。
【落とし穴3】データ準備への「甘い認識」が予算と時間を溶かす泥沼
AIプロジェクトにおいて、AIモデルの開発や導入後の運用フェーズにばかり注目が集まり、プロジェクトの初期段階で最も重要かつ時間とコストがかかる「データ準備」の工数が過小評価されがちです。この認識の甘さが、プロジェクトの遅延や予算超過を引き起こす大きな要因となります。
データ準備は、AIプロジェクトを成功させるための「見えない土台」であり、その重要性を理解することは不可欠です。
AI導入「前」に潜む、データクレンジング・前処理の「見えない工数」
AIを学習させるためには、データは特定の形式に統一され、欠損値が適切に処理され、ノイズが除去されている必要があります。この一連の作業を「データクレンジング」や「データ前処理」と呼びますが、その作業量は想像以上に膨大です。
具体的には、以下のような作業が含まれます。
- データ統合:複数のデータベースやシステムに散らばるデータを一つに集約する作業。システム間の連携不足やデータ形式の違いにより、非常に手間がかかります。
- 重複排除・表記ゆれ修正:顧客情報や商品名などに存在する重複データや、異なる表記を統一する作業。手作業では限界があり、専門的なツールやスキルが求められます。
- 欠損値補完:データの一部が欠けている場合、統計的な手法や推論によって補完する作業。不適切な補完はAIの学習を歪めるため、慎重な検討が必要です。
- データ形式変換:AIモデルが処理しやすいように、数値データやカテゴリデータを変換する作業。
これらの作業は、AIモデルの開発そのものよりも地味で目立ちにくいですが、プロジェクト全体の工数の50%以上を占めることも珍しくありません。しかし、多くの計画段階では、この「見えない工数」が軽視され、結果的にプロジェクトの遅延や、追加予算の要求につながってしまうのです。
データ準備にかかる見えないコストと時間の具体例は以下の通りです。
データ準備にかかる見えないコストと時間の例
- 人件費:複数のデータソースからの手作業によるデータ抽出、Excelなどでの手作業クレンジングにかかる担当者の時間。
- ツール費用:データ統合・ETLツール、データ品質管理ツールなど、専門的なツールの導入費用やライセンス費用。
- 外部委託費用:複雑なデータクレンジングや前処理を専門業者に委託する場合の費用。
- 認識のずれ:開発者とビジネスサイドで、必要なデータの形式や品質に関する認識が合致せず、手戻りが発生するコスト。
データ準備は、AIプロジェクトの「土台作り」です。この土台がしっかりしていないと、その上にどんなに優れたAIモデルを構築しようとしても、不安定で崩れやすいものとなってしまいます。
教師データ作成(アノテーション)の専門性と、見積もり以上の高コスト
画像認識や音声認識、自然言語処理といった分野のAIでは、AIが何を学習すべきかを教えるための「教師データ」が必要です。この教師データを作成する作業を「アノテーション(データのラベル付け)」と呼びます。
例えば、画像認識AIを開発する際には、写真の中に何が写っているのか(例:「犬」「猫」「自動車」)、どこにその対象物があるのかを一つずつ指定していく必要があります。自然言語処理AIでは、文章のどの部分が「肯定的な意見」で、どの部分が「否定的な意見」かといったラベル付けを行います。
このアノテーション作業は、非常に手間がかかる上に、専門知識と高い集中力を要します。
- 膨大な作業量:AIの性能を高めるためには、数万、数十万、場合によっては数百万という大量の教師データが必要になります。
- 専門性と品質:ラベル付けの品質がAIの性能に直結するため、対象分野に関する専門知識や、一貫したルールに基づいた作業が求められます。品質が低いアノテーションデータでは、AIは正しく学習できません。
- 人件費:これらの作業を内製する場合でも、外部の専門ベンダーに委託する場合でも、膨大な人件費や委託費用が発生します。多くの場合、プロジェクトの計画段階でこのコストが過小評価され、後から予算を圧迫する要因となります。
データアノテーションは、AIプロジェクトの成果を直接左右する重要な工程でありながら、その専門性とコストが見積もりから漏れやすい盲点です。プロジェクトの早い段階で、必要な教師データの量と質、それに伴うコストと期間を正確に見積もり、計画に組み込むことが極めて重要となります。
失敗から学ぶ:AIプロジェクトを成功に導く「データ戦略」と経営層の役割
AIプロジェクトを成功に導くためには、AIモデル開発だけでなく、データそのものに対する戦略的なアプローチが不可欠です。ここでは、AI投資を成功させるための具体的なデータ戦略と、経営層が果たすべき重要な役割について解説します。
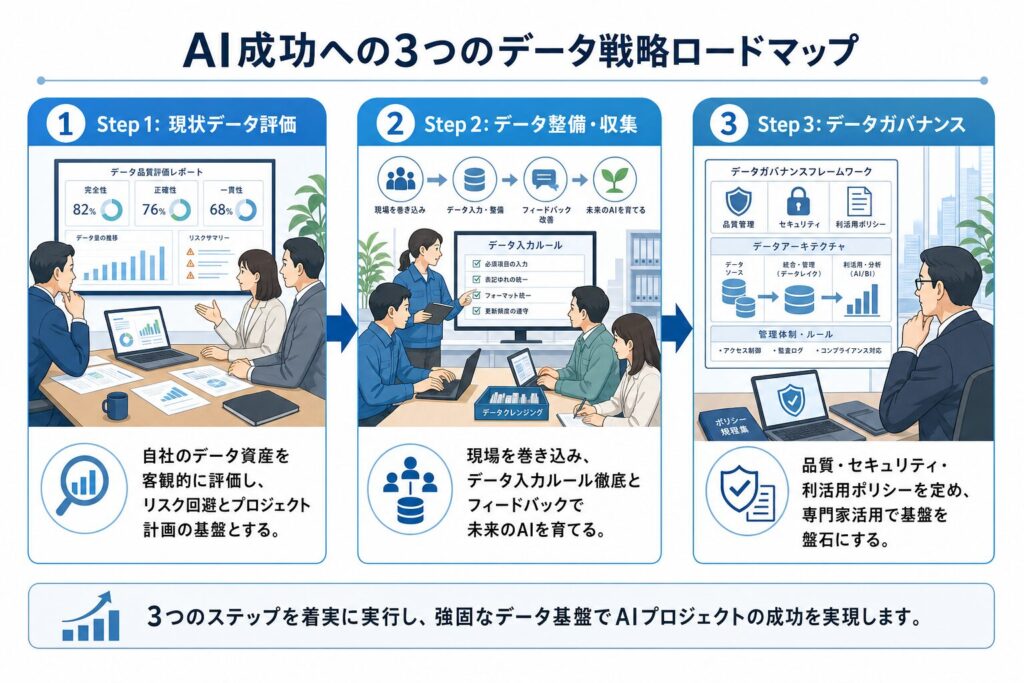
プロジェクト着手前に必須!「現状データ評価」でリスクを回避する
AIプロジェクトを始める前に、まず自社がどのようなデータを保有しているのか、そのデータがAI活用にどの程度適しているのかを客観的に評価する「現状データ評価(データアセスメント)」を実施することが極めて重要です。このステップを怠ると、プロジェクトの進行中に予期せぬデータの問題に直面し、大幅な遅延やコスト増加につながるリスクが高まります。
データ評価では、以下の点を詳細に確認します。この評価は、プロジェクトの現実的な目標設定と計画立案の基盤となります。
データ評価の主要チェックポイント
- データの種類と量:AIで解決したい課題に対し、必要なデータが十分に存在するか。どのようなデータソースがあるか。
- データの品質:データの正確性、網羅性、一貫性は保たれているか。欠損値や重複、表記ゆれはどの程度存在するか。
- データの鮮度:データは最新の状態に保たれているか。リアルタイム性が求められる場合は対応可能か。更新頻度はどうか。
- データの形式と構造:データはAIが学習しやすい形式に統一されているか。構造化されているか、非構造化データか。変換の難易度は。
- データへのアクセス権限:必要なデータに法規制や社内規約上、適切にアクセスできるか。アクセス手続きの複雑さは。
- データの保管場所:データが複数のシステムや場所に分散している場合、統合の難易度はどうか。
- 個人情報保護・セキュリティ:個人情報を含むデータの場合、プライバシー保護やセキュリティ対策は万全か。匿名化等の措置は必要か。
このデータ評価を通じて、現在のデータでAIプロジェクトの目標達成が可能かどうか、どのようなデータ整備が必要か、あるいは追加でどのようなデータ収集が必要となるかといった「現実的な課題」を洗い出すことができます。これにより、プロジェクトの初期段階で潜在的なリスクを特定し、より正確な計画と見積もりを立て、手戻りを最小限に抑えることが可能となるのです。
現場を巻き込む「データ整備・収集体制」の確立で、未来のAIを育てる
データは一度整備したら終わりではありません。ビジネスの変化や時間の経過とともに、新たなデータが生成され、既存のデータも変化していきます。そのため、継続的なデータ品質の維持・向上と、AIが必要とするデータの収集を効率的に行うための体制構築が不可欠です。
この体制構築において、最も重要なのが「現場の巻き込み」です。データは現場の業務活動から生まれるものであり、データ入力の最前線にいる現場担当者がデータ品質の重要性を理解し、積極的に協力してくれるかどうかが、継続的なデータ整備の鍵を握ります。
具体的には、以下の取り組みが考えられます。
- データ入力ルールの徹底と標準化:部署や担当者間でばらつきがちなデータ入力規則を明確にし、社内全体で標準化します。研修やマニュアル整備も効果的です。必要に応じて、入力支援ツールや自動チェック機能の導入を検討します。
- データ品質チェックの仕組み:定期的なデータ品質監査や、システムによる自動チェック機能などを導入し、問題のあるデータを早期に発見・修正できる仕組みを構築します。異常値を自動で検知し、担当者にアラートを出すような仕組みも有効です。
- 現場からのフィードバックループ:AIが現場で使われる中で、AIの判断結果に対する現場からのフィードバック(例:「この予測は外れた」「この分類は間違っている」)を収集し、それを新たな学習データとして活用する仕組みを構築します。これにより、AIは継続的に学習し、進化できます。
- データに対する意識改革:データは「AIの燃料」であり、その品質がビジネスの成果を左右するという意識を、経営層から現場まで全社的に共有する文化を醸成します。データ入力の品質が評価基準の一つになるような制度設計も有効でしょう。
現場がデータの重要性を認識し、自らデータ品質向上に貢献する文化が醸成されれば、AIは単なるツールではなく、企業の成長を支える「未来の知性」として育っていくでしょう。
データガバナンスの構築と専門家活用で、AI活用の基盤を盤石にする
AIプロジェクトの成功を単発で終わらせず、企業全体で持続的なAI活用を実現するためには、強固な「データガバナンス」の構築と、データ・AIに関する専門家(データサイエンティスト、データエンジニアなど)の活用が不可欠です。
データガバナンスとは、企業が保有するデータの品質、セキュリティ、プライバシー、利活用に関する方針、規則、プロセスを定めて、それらを適切に運用するための体制のことです。これにより、データが企業の重要な資産として最大限に活用され、同時にリスクも適切に管理されるようになります。
データガバナンスを構築する上で、主要な要素は以下の通りです。
データガバナンス構築の主要要素
- データ品質管理:データ入力から利用までのライフサイクル全体で、データの正確性、完全性、一貫性を保証するプロセス。定期的な品質チェックと改善サイクルを確立する。
- データセキュリティ・プライバシー保護:機密情報や個人情報の漏洩防止、アクセス制御、法規制(GDPR、個人情報保護法など)遵守のための体制。セキュリティポリシーの策定と実施。
- データ利活用ポリシー:どのデータを、誰が、どのような目的で、どのように利用できるかを明確にするルール。データ利用申請プロセスや承認フローを整備する。
- データ所有権と責任:各データの所有者を明確にし、その品質や管理に対する責任を明確化。データカタログを作成し、データの所在と責任者を一元管理する。
- データ標準化:社内全体でデータ定義や形式を標準化し、システム間の連携やデータ統合を容易にする。マスターデータ管理(MDM)の導入も視野に入れる。
このようなデータガバナンスを構築するためには、経営層がその重要性を深く理解し、トップダウンで推進する強いリーダーシップが必要です。また、データの収集・整備、分析、AIモデル開発、運用には高度な専門知識が求められるため、社内にデータサイエンティストやデータエンジニアといった専門人材を育成・配置するか、あるいは外部の専門パートナーと連携することも検討すべきです。
彼らは、データの価値を最大限に引き出し、AIプロジェクトが技術的にもビジネス的にも成功するための羅針盤となる存在です。経営層がデータガバナンスの旗振り役となり、専門家を適切に活用することで、AI活用の基盤を盤石にし、持続的な競争優位性を確立できるでしょう。
まとめ:データ中心のアプローチこそ、AI投資を成功させる唯一の道
AIは今日のビジネスにおいて強力な変革をもたらす可能性を秘めた技術です。しかし、そのポテンシャルを最大限に引き出し、期待通りの成果を得るためには、単に最新のAIモデルを導入するだけでは不十分です。AIプロジェクトの成功は、AIの「燃料」であるデータの質と、それらを戦略的に管理・活用する企業文化にかかっています。
本記事でご紹介したように、AIプロジェクトが「期待外れに終わる」「使えないと烙印を押される」根本的な理由は、データの質の低さ、偏り、不足、そしてデータ準備への認識の甘さにあります。これらは全て、経営層が見落としがちな「データ」という盲点に起因するものです。
AI投資を無駄にしないためには、以下のデータ中心のアプローチを強力に推進してください。
- AIプロジェクト着手前の徹底した「現状データ評価」:自社のデータ資産を客観的に見つめ直し、AI活用における課題と可能性を明確にする。
- 現場を巻き込んだ「データ整備・収集体制」の確立:データは日々の業務から生まれるものであり、現場の意識改革と継続的な協力が不可欠。
- 強固な「データガバナンス」の構築と専門家の活用:データの品質、セキュリティ、利活用に関する明確なルールを定め、専門知識を持つ人材を適切に配置する。
経営層の皆様には、AIを単なる「ツール」として捉えるのではなく、「データ」と一体となった企業の新たな「知性」として捉え、データへの投資と戦略を経営の最優先事項の一つとして位置付けていただきたいと強く申し上げます。データ中心のアプローチこそが、AI投資を成功させ、企業の未来を切り拓く唯一の道となるでしょう。