
目次
本記事のポイント
- RAG導入の成功には、高品質なデータソースの選定、適切な前処理、そして最適なベクトルデータベースの構築が不可欠であることを理解できます。
- LLMが抱えるハルシネーション問題の克服から、情報の鮮度や透明性の向上といったRAGの核心的なメカニズムとビジネス価値を把握できます。
- 現状分析からデータパイプライン設計、運用・保守に至るまで、RAG向けデータ基盤を構築するための具体的なステップと実践的考慮点を解説します。
- PineconeやWeaviateといった主要ベクトルデータベースから、データ統合・変換のETL/ELTツールまで、RAGデータ基盤を支える主要技術スタックを比較検討できます。
- データ鮮度、コスト、セキュリティといったRAG導入における現場の課題に対し、具体的な解決策とベストプラクティスを得られます。
RAG導入の成否を分ける!データ基盤構築の全て
企業競争力向上の切り札として、AI技術の活用は欠かせません。特に近年、大規模言語モデル(LLM)の進化は目覚ましく、その応用範囲は広がりを見せています。しかし、LLM単体での運用には限界があり、特定の業務や企業固有の知識を活用する場面では、期待通りの成果を出せないケースも少なくありません。そこで注目されるのが、RAG(Retrieval-Augmented Generation:検索拡張生成)です。
RAGは、外部の情報検索システムとLLMを組み合わせ、より正確で信頼性の高い回答を生成するフレームワークです。この技術は、LLMの持つ汎用的な言語理解能力と、企業が保有する専門性の高いデータを結びつける架け橋となります。しかし、RAGの導入は単にLLMと検索システムを連携させるだけでは成功しません。その成否を大きく左右するのが、「データ基盤」の設計と構築です。
技術担当者の皆様にとって、RAG導入プロジェクトは、新たな技術領域への挑戦であり、同時に既存のデータインフラを見直し、最適化する絶好の機会でもあります。本記事では、RAG導入を成功に導くためのデータ基盤設計戦略に焦点を当て、具体的なアーキテクチャや実践的な考慮点を深く掘り下げていきます。
なぜ今、RAGとデータ基盤が技術担当者の注目を集めるのか?
LLMは、インターネット上の膨大なテキストデータから学習しているため、一般的な知識や常識に基づいた回答は得意です。しかし、企業の内部ドキュメント、特定業界の専門知識、最新の社内データといった固有の情報については学習しておらず、これらに基づいた正確な回答を生成することはできません。さらに、学習データの限界から、存在しない情報を事実であるかのように生成する「ハルシネーション(幻覚)」という問題も抱えています。
このようなLLMの課題を解決し、ビジネス現場で真に役立つAIシステムを構築するため、RAGの導入が喫緊の課題となっています。RAGは、LLMが回答を生成する際に、企業が持つ信頼性の高いデータソースから関連情報をリアルタイムで検索し、それを参照しながら回答を生成します。これにより、情報の正確性、最新性、信頼性が飛躍的に向上し、ハルシネーションのリスクを大幅に低減できます。
このRAGの特性を最大限に引き出すには、いかに迅速かつ正確に、そして網羅的に関連情報を取得できるかが鍵です。そのためには、質の高いデータを効率的に管理・検索できるデータ基盤の存在が不可欠となります。技術担当者としては、RAGのアルゴリズムを理解するだけでなく、その土台となるデータ基盤の設計・構築能力が求められます。
LLMの可能性を最大限に引き出すRAGの核心
RAGは、LLMの卓越した言語生成能力と、外部知識の検索能力を融合させ、ビジネスにおける様々な課題解決に貢献します。例えば、顧客サポートのFAQシステム、社内ナレッジベース、研究開発における文献調査など、幅広い分野でその効果を発揮できます。
この技術の核心的なメリットは以下の通りです。
RAGの技術的メリット
- ハルシネーションの抑制: 事実に基づかない情報の生成リスクを大幅に低減し、信頼性の高い回答を可能にします。
- 情報の最新性: LLMの学習データが更新されるのを待つことなく、常に最新の企業情報や市場データに基づいて回答を生成できます。
- 回答の根拠提示: LLMが参照した情報源(ドキュメント、データベースのエントリなど)を提示できるため、回答の透明性と説明責任が向上します。
- ドメイン固有知識の活用: 企業固有の専門用語や内部情報をLLMに学習させることなく活用でき、モデル再学習のコストと時間を削減します。
- 情報の検索性向上: ユーザーは自然言語で質問するだけで、関連性の高い情報を瞬時に見つけ出せるようになります。
これらのメリットを享受するためには、データ基盤がRAGシステムの「心臓部」として機能する必要があります。高品質なデータの収集、効率的なインデックス作成、そして高速な検索メカニズムが、RAGのパフォーマンスを決定づけるのです。
RAG(Retrieval-Augmented Generation)の基本メカニズムを理解する
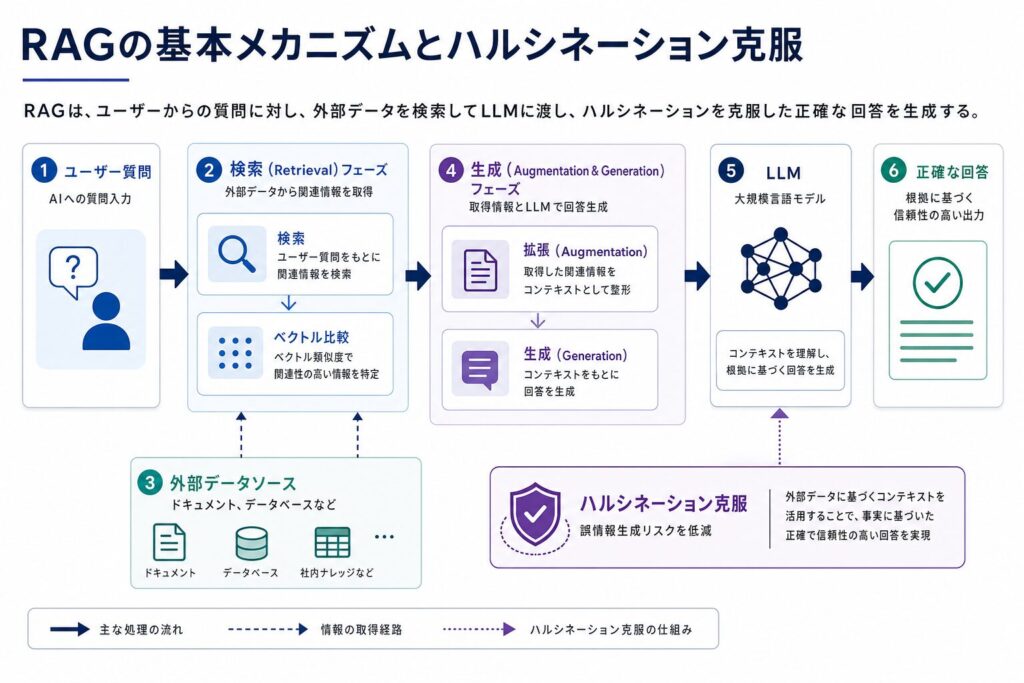
RAGは、大規模言語モデルが持つ汎用性と、企業固有の専門知識を結びつける画期的なアプローチです。このセクションでは、RAGがどのように機能し、LLMの主要な課題をいかに解決しているのか、その基本メカニズムを技術的な視点から掘り下げていきます。
LLMの弱点「ハルシネーション」を克服するRAGの仕組み
LLMは、学習データに基づいた統計的なパターンから回答を生成します。このプロセスにおいて、学習データに含まれていない情報や、文脈を誤って解釈した場合に、あたかも事実であるかのような誤った情報を生成してしまうことがあります。これが「ハルシネーション」と呼ばれる現象です。ハルシネーションは、ビジネスにおけるAI活用において、誤情報による意思決定や顧客への誤案内といった深刻なリスクをもたらします。
RAGは、このハルシネーションの問題を克服するために、以下の二つのフェーズを統合します。
- Retrieval(検索)フェーズ:ユーザーからの質問が入力されると、RAGシステムはまず、社内ドキュメント、データベース、ウェブサイトなど、指定された信頼性の高い外部データソースから、質問に関連する情報(ドキュメント、テキストチャンクなど)を検索・取得します。この検索は、質問とデータの「意味的な関連性」に基づいて行われることが多く、ベクトル検索が中心的な役割を担います。
- Augmentation & Generation(拡張・生成)フェーズ:検索フェーズで取得された関連情報が、プロンプトの一部としてLLMに与えられます。LLMは、このプロンプトと検索された情報を「コンテキスト」として利用し、質問に対する回答を生成します。これにより、LLMは自身の学習データだけでなく、提供された外部情報を根拠として回答を生成するため、事実に基づいた、より正確で信頼性の高い出力を期待できます。
この仕組みにより、RAGはLLMが「知らないこと」に対して推測で回答するのではなく、「参照できる情報」に基づいて回答するよう誘導します。結果として、ハルシネーションのリスクを大幅に低減し、回答の信頼性を高めることが可能になります。
RAGがもたらすビジネス価値と技術的メリット
RAGの導入は、企業に多大なビジネス価値と技術的メリットをもたらします。これらは、単にAIの精度向上に留まらず、運用コストの削減や新たなビジネス機会の創出にも繋がります。
RAGの主なビジネス価値
- 顧客体験の向上: 顧客からの問い合わせに対して、パーソナライズされ、かつ正確な情報に基づいた回答を迅速に提供できます。
- 従業員の生産性向上: 社内ナレッジや専門文書へのアクセスが容易になり、情報探索にかかる時間と労力を削減し、業務効率を高めます。
- 意思決定の質の向上: 最新かつ正確な社内データや市場データに基づいた分析やレポート生成が可能となり、データドリブンな意思決定を促進します。
- コンプライアンスとガバナンスの強化: 生成される情報源を特定できるため、規制要件への対応や監査証跡の確保が容易になります。
RAGの技術的メリット
- モデルの再学習不要: LLMの基盤モデルを再学習させることなく、新しい情報やドメイン固有の知識をシステムに組み込めます。これは、コストと時間の大幅な節約に繋がります。
- 説明可能性の向上: 生成された回答がどの情報源に基づいて生成されたかを明確に示せるため、AIシステムの「ブラックボックス化」を防ぎ、信頼性を確保します。
- 情報の鮮度維持: 外部データソースをリアルタイムまたは頻繁に更新することで、LLMが常に最新の情報に基づいて回答を生成できるようになります。
- 柔軟なシステム設計: LLM、検索エンジン、データストアといった各コンポーネントを独立して選択・最適化できるため、システムの柔軟性と拡張性が高まります。
これらのメリットは、特に大規模なデータ資産を持つ企業や、常に最新の情報に基づいた意思決定が求められる業界にとって、RAGが不可欠な技術であることを示します。次のセクションでは、これらのメリットを最大限に引き出すためのデータ基盤の要件について詳しく見ていきましょう。
実務で使える!RAG導入に不可欠なデータ基盤の要件
RAGシステムの性能は、その基盤となるデータに大きく依存します。どんなに優れたLLMや検索アルゴリズムを用いても、データ基盤が不十分であれば、期待する成果は得られません。ここでは、RAGの導入を成功させるために、技術担当者が考慮すべきデータ基盤の主要な要件を実務的な視点から解説します。
RAGの精度を左右する「高品質なデータソース」の見極め方
RAGにおける「高品質なデータ」とは、単に情報量が多いことだけを指すのではありません。正確性、最新性、網羅性、そして信頼性が兼ね備わっていることが重要です。データソースの選定と準備は、RAGの応答精度を直接的に左右する最初のステップとなります。
まず、社内にどのようなデータが存在し、それがRAGシステムでどのように活用されるかを洗い出す必要があります。
RAGにおけるデータソース選定のチェックリスト
- 目的との整合性: RAGで解決したい具体的なビジネス課題に対して、そのデータがどれだけ関連性が高いか。
- 信頼性と権威性: データが公式な情報源や専門家によって検証されているか。誤情報や古い情報が含まれていないか。
- 網羅性と粒度: 必要な情報が欠落していないか、また、情報の粒度がRAGの検索・生成に適しているか。
- 更新頻度: データの鮮度がどの程度求められるか。更新頻度の低い固定情報なのか、リアルタイム性が求められる動的な情報なのか。
- アクセス性とフォーマット: 既存のシステムからデータに容易にアクセスできるか。PDF、Webページ、データベース、APIなど、多様なフォーマットへの対応能力。
- セキュリティとガバナンス: 機密情報や個人情報が含まれていないか、適切なアクセス制御や匿名化が施されているか。
これらの点を踏まえ、まずは社内のドキュメント(契約書、報告書、技術マニュアル)、FAQ、CRMデータ、Webサイトコンテンツ、データベース(リレーショナルDB、NoSQL DB)などを候補として洗い出し、優先順位を付けていくことが肝要です。特に非構造化データ(テキスト、画像など)の扱いがRAGでは重要になるため、これらのデータを適切に構造化・整理するアプローチも同時に検討する必要があります。
応答品質を向上させる「データ前処理」と「特徴量エンジニアリング」
データソースを選定した後は、RAGが効率的かつ正確に情報を検索・利用できるよう、適切な前処理と特徴量エンジニアリングを施す必要があります。これはRAGの応答品質を直接的に高める重要なプロセスです。
- クリーニングと正規化:データ品質を高めるために、不要情報の除去や表記ゆれの統一を行う工程です。
- ノイズ除去:不要なHTMLタグ、広告、重複コンテンツ、特殊文字などを除去します。
- 表記ゆれの統一:固有名詞や専門用語の表記ゆれを統一し、検索の一貫性を高めます。
- 誤字脱字の修正:データの品質を向上させ、検索漏れを防ぎます。
- チャンキング(Chunking):取得したドキュメントを、LLMのトークン制限や検索の粒度に合わせて、適切なサイズの「チャンク(断片)」に分割する作業です。
- チャンクサイズが大きすぎると関連性の低い情報も含まれ、小さすぎると文脈が失われるため、最適なサイズを見極めることが重要です。テキストの区切り(段落、セクション、ページ)や、セマンティックな意味を考慮した分割が効果的です。オーバーラップ(重複)を持たせることで、文脈の連続性を保つ手法も一般的です。
- エンベディング(Embedding):各チャンクを、意味的な情報を保持した数値ベクトル(埋め込みベクトル)に変換するプロセスです。
- これは、質問のベクトルとデータチャンクのベクトル間の距離を測ることで、意味的な類似性を判断するために不可欠です。
- エンベディングモデルの選定も重要です。OpenAIの`text-embedding-ada-002`やHugging Faceのオープンソースモデルなど、タスクや言語特性、コストを考慮して最適なモデルを選びます。ドメイン特化のエンベディングモデルを利用することで、精度をさらに向上できる場合があります。
- メタデータの付与:各チャンクに、元のドキュメント名、作成者、作成日、カテゴリ、キーワード、アクセス権限などの付帯情報を追加する作業です。
- メタデータは、検索結果のフィルタリング、並べ替え、およびRAGの回答生成時にLLMに与えるコンテキストの質を高めるために非常に役立ちます。例えば、「2023年以降の営業戦略に関するドキュメントのみを検索」といった高度な検索が可能になります。
これらの前処理と特徴量エンジニアリングは、データパイプラインとして自動化し、データの更新に合わせて常に最新の状態を保つことが求められます。
高速な情報検索を実現する「ベクトルデータベース」の選定基準
RAGの検索フェーズの中核を担うのが、ベクトルデータベース(Vector Database)です。前処理によって生成された埋め込みベクトルを効率的に格納し、高速な類似度検索(Nearest Neighbor Search: KNNまたはApproximate Nearest Neighbor Search: ANN)を実行するために設計されています。ベクトルデータベースの選定は、RAGシステムのパフォーマンスとスケーラビリティに直結します。
ベクトルデータベース選定の主要基準
- 検索速度とスケーラビリティ: 大量のベクトルデータに対して、どれだけ高速に、かつ負荷が増大しても安定して検索を実行できるか。
- インデックスアルゴリズム: ANN検索における多様なインデックス手法(HNSW, IVF_FLATなど)への対応。
- メタデータフィルタリング: ベクトル検索と同時に、メタデータに基づくフィルタリング(例: 特定の部署のドキュメントのみ検索)が効率的に行えるか。
- データ管理機能: ベクトルの追加、更新、削除が容易か。データの一貫性や耐久性に関する機能。
- APIと開発者エクスペリエンス: Python, Javaなどのクライアントライブラリの充実度、REST APIの使いやすさ。
- コスト: クラウドサービスのマネージドサービスを利用する場合の料金体系、オンプレミスやセルフホストでの運用コスト(インフラ、運用負荷)。
- エコシステムとの連携: LangChain, LlamaIndexといったRAGフレームワークや、既存のデータパイプラインツールとの統合のしやすさ。
- オープンソースか商用サービスか: 自社での運用負荷と、ベンダーサポートや高度な機能の必要性を比較検討します。
主要なベクトルデータベースには、Pinecone、Weaviate、Milvus、Qdrant、Chromaなどがあり、それぞれ特徴が異なります。後続のセクションで詳細に比較しますが、プロジェクトの要件と既存の技術スタックに最も適したものを慎重に選ぶことが成功への鍵となります。
RAG向けデータ基盤構築の具体的なステップと実践的考慮点
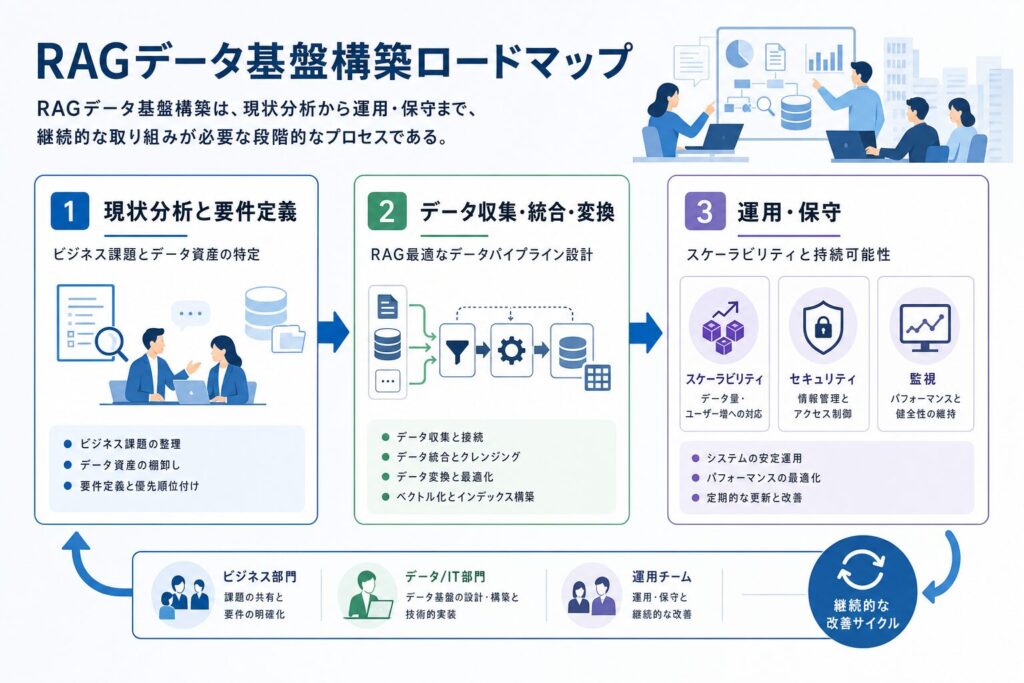
RAGの導入は、単一のツール導入だけでなく、一連のシステム設計と構築プロセスを伴います。ここでは、RAG向けデータ基盤を効果的に構築するための具体的なステップと、それぞれのフェーズで技術担当者が考慮すべき実践的なポイントを解説します。
現状分析と要件定義:あなたのビジネスに最適なRAG基盤とは
RAGプロジェクトを開始する前に、まず現状のビジネス課題、既存のデータ資産、そしてシステム要件を詳細に分析し、明確な要件定義を行うことが不可欠です。このフェーズでの見落としは、後の工程で大きな手戻りやコスト増に繋がる可能性があります。
- ビジネス課題の特定とユースケースの明確化:RAGを導入することで解決したい具体的な業務課題と、ターゲットとなるユーザーのニーズを明確にするステップです。
- RAGを導入することで、具体的にどのような業務課題を解決したいのかを明確にします。(例: 顧客サポートの対応時間短縮、社内情報検索の効率化、特定ドメインの専門知識を活用したコンテンツ生成など)
- ターゲットとなるユーザー(顧客、従業員、開発者など)とそのニーズを深く理解します。
- データ資産の棚卸しと評価:現在保有しているデータソースを全て洗い出し、RAGシステムで活用可能かを評価します。
- 現在保有しているデータソース(ドキュメント、データベース、Webコンテンツ、APIなど)を全て洗い出します。
- それぞれのデータの量、種類(構造化・非構造化)、品質、鮮度、アクセス頻度、セキュリティ要件などを評価します。RAGへの適合性、前処理の難易度を判断します。
- データガバナンスの現状を確認し、RAGで利用するデータの利用許諾、プライバシー、機密性に関する規制や社内ポリシーへの対応を検討します。
- 技術的要件の定義:RAGシステムのパフォーマンス、スケーラビリティ、可用性、セキュリティ、統合性に関する具体的な目標値を設定する工程です。
- パフォーマンス要件:平均応答時間、同時アクセス数、検索レイテンシなどの目標値を設定します。
- スケーラビリティ要件:将来的なデータ量の増加、ユーザー数の増加にどのように対応するかを定義します。
- 可用性要件:サービス停止に対する許容範囲(SLA)と、それを実現するためのアーキテクチャ(冗長化、バックアップなど)を検討します。
- セキュリティ要件:データアクセス制御、暗号化、監査ログ、個人情報保護など、RAGシステム全体におけるセキュリティ基準を確立します。
- 統合要件:既存のシステム(CRM、ERP、ナレッジベース、BIツールなど)との連携方法を定義します。
このフェーズで、最小限の機能を持つMVP(Minimum Viable Product)を定義し、スモールスタートで検証を重ねるアプローチも有効です。
データ収集・統合・変換:RAGに最適なデータパイプラインの設計
要件定義に基づき、RAGに必要なデータを効率的に収集、統合、変換するためのデータパイプラインを設計・構築します。これは、RAGシステムの安定稼働とパフォーマンス維持の要となります。
- データ収集メカニズムの確立:データの更新頻度や性質に応じて、効率的な収集方法を決定する工程です。
- バッチ処理:定期的なデータ更新に適しています。FTP、データベースからのCSVエクスポート、S3バケットからの読み込みなど。
- ストリーミング処理:リアルタイムに近い鮮度が求められるデータ(例: 新着ニュース、チャットログ)に適しています。Apache Kafka、Amazon Kinesisのようなメッセージキューやストリーム処理プラットフォームを活用します。
- API連携:Salesforce、ZendeskなどのSaaSや、Webクローラーを利用して外部情報を取得します。
- データ統合と変換(ETL/ELT):収集した多様な形式のデータをRAGに適した共通フォーマットに統合し、必要な前処理を施すプロセスです。
- 収集した多様な形式のデータをRAGに適した共通フォーマットに統合します。データレイクやデータウェアハウスを中間層として活用することが一般的です。
- 前述の「データ前処理」(クリーニング、チャンキング、エンベディング、メタデータ付与)を自動化するパイプラインを構築します。
- ツールとしては、Apache Airflow、Prefect、dbt(data build tool)などのワークフロー管理ツールや、Apache Spark、AWS Glue、Azure Data Factoryのようなデータ処理サービスが活用されます。
- データ品質チェックの仕組みをパイプラインに組み込み、異常値を検知・修正するフローを設けます。
- ベクトルデータベースへのインデックス作成:前処理されたテキストチャンクとその埋め込みベクトルをベクトルデータベースに効率的に格納する工程です。
- 前処理されたテキストチャンクとその埋め込みベクトルをベクトルデータベースに格納します。
- インデックス作成の効率化:新規データ追加、既存データ更新、削除のプロセスを自動化し、定期的にインデックスを再構築する戦略を立てます。特に、大量データの場合、増分更新の仕組みは重要です。
データパイプラインは、堅牢性、スケーラビリティ、監視可能性を考慮して設計することが重要です。障害発生時のリカバリメカニズムや、パイプラインの実行状況をリアルタイムで監視する仕組みも不可欠です。
運用・保守:スケーラビリティと持続可能性を考慮したアーキテクチャ
RAGデータ基盤は、構築したら終わりではありません。継続的な運用・保守を通じて、システムのパフォーマンスを最適に保ち、将来的な変化に対応できる持続可能なアーキテクチャを維持することが求められます。
- 監視とアラート:システムの健全性を常時チェックし、異常が発生した際に迅速に対応するための仕組みです。
- ベクトルデータベースのクエリ応答時間、リソース使用率(CPU, メモリ, ディスクI/O)、エラー率などを常時監視します。
- データパイプラインの実行状況、データ取り込みの遅延、品質チェックのエラーなどを監視し、異常を検知した際にはアラートを発する仕組みを構築します。
- RAGシステムの全体的なパフォーマンス(検索の関連性、LLMの応答品質)も定期的に評価し、閾値を超えた場合にアラートを出すように設定します。
- パフォーマンスチューニング:ログデータ分析に基づき、システムのボトルネックを特定し、継続的に改善していく活動です。
- ログデータを分析し、ボトルネックとなっている部分を特定します。
- ベクトルデータベースのインデックス設定の最適化、クエリパラメータの調整、チャンキング戦略の見直しなどを定期的に行い、検索速度と精度のバランスを取ります。
- 利用しているエンベディングモデルやLLMモデルのバージョンアップも検討し、最新の技術動向を取り入れます。
- スケーラビリティの確保:データ量やユーザーアクセスの増加に柔軟に対応できるよう、システムの拡張性を考慮する設計です。
- データ量の増加やユーザーアクセスの急増に対応できるよう、ベクトルデータベースやデータパイプラインが水平スケーリング可能であることを確認します。
- クラウドサービスを利用している場合は、オートスケーリング機能の活用や、予約インスタンスによるコスト最適化を検討します。
- セキュリティとデータガバナンス:RAGシステムが扱うデータの機密性を保ち、法規制や社内ポリシーを遵守するための継続的な取り組みです。
- アクセス制御(RBAC: Role-Based Access Control)を厳格に適用し、データへの不正アクセスを防ぎます。
- データの暗号化(保管時と転送時)を徹底します。
- 定期的なセキュリティ監査と脆弱性診断を実施し、対策を講じます。
- データのライフサイクル管理(保存期間、アーカイブ、削除ポリシー)を確立し、コンプライアンス要件を満たします。
- バージョン管理と変更管理:データパイプラインやシステム設定の変更を適切に管理し、安定した運用を維持するためのプロセスです。
- データパイプラインのスクリプト、設定ファイル、RAGシステムの設定などをバージョン管理システム(Gitなど)で管理します。
- 変更管理プロセスを確立し、本番環境へのデプロイ前に十分なテストを実施します。
持続可能なRAGデータ基盤は、これらの運用・保守活動を継続的に行うことで初めて実現されます。DevOpsのプラクティスを取り入れ、開発と運用が密接に連携する体制を構築することが理想的です。
RAGデータ基盤を支える主要ツールと技術スタック
RAGデータ基盤を構築するには、様々なコンポーネントとそれらを支える技術スタックの選定が不可欠です。市場には多様なツールが存在するため、それぞれの特徴を理解し、自社の要件に最も適したものを選択することが重要です。
主要ベクトルデータベース徹底比較:オープンソースと商用サービス
ベクトルデータベースは、RAGの検索性能を直接左右する最も重要なコンポーネントの一つです。ここでは、主要な選択肢を比較検討します。
主要ベクトルデータベースの比較
- Pinecone:フルマネージドのクラウドサービスで、高いスケーラビリティと簡単な運用が魅力です。複雑なインデックス管理やシャーディングを意識する必要がなく、高速なANN検索を提供します。
- メリット: 運用負荷が低い、高性能、多機能(メタデータフィルタリング、ネームスペースなど)。
- デメリット: コストが高めになりやすい、ベンダーロックインのリスク。
- 利用シーン: 大規模なRAGシステム、運用リソースを抑えたい企業。
- Weaviate:オープンソース(Apache 2.0 License)でありながら、セルフホスト、クラウド(WCS)、ハイブリッドデプロイが可能です。GraphQL APIやOpenAPIによる強力なデータモデル定義と検索機能が特徴で、メタデータフィルタリングも強力です。
- メリット: オープンソースで柔軟性が高い、活発なコミュニティ、セマンティック検索とグラフ機能の統合。
- デメリット: セルフホストの場合の運用負荷、比較的新しい技術であるため学習コスト。
- 利用シーン: データモデルを細かく制御したい、オープンソースを志向する企業。
- Milvus / Zilliz:Milvusはオープンソースのベクトルデータベースで、高いスケーラビリティと性能を誇ります。ZillizはMilvusを基盤としたマネージドサービスを提供しており、大規模なデータセットと高スループットに対応します。
- メリット: オープンソースの利点、大規模データ対応、柔軟なインデックス選択。
- デメリット: 運用が複雑になりがち(セルフホストの場合)、学習コスト。
- 利用シーン: 超大規模なベクトル検索システム、高いカスタマイズ性を求める企業。
- Qdrant:オープンソース(Apache 2.0 License)でRust言語で開発されており、高速性と堅牢性が特徴です。強力なフィルタリング機能とペイロードインデックスを備え、セルフホストとマネージドサービス(Qdrant Cloud)を提供しています。
- メリット: 高性能、豊富なフィルタリングオプション、Kubernetesネイティブ。
- デメリット: Milvus同様、セルフホストの運用負荷。
- 利用シーン: リアルタイム性を重視するRAGシステム、Rustエコシステムに馴染みがある企業。
- Chroma:オープンソースでPythonネイティブな軽量ベクトルデータベースです。ローカルでの開発や小規模なプロジェクトに適しており、LangChainやLlamaIndexとの統合が容易です。
- メリット: セットアップが簡単、開発が容易、Pythonエコシステムとの親和性。
- デメリット: 大規模なプロダクション環境でのスケーラビリティに限界がある場合がある。
- 利用シーン: プロトタイピング、小規模なRAGアプリケーション。
その他、Redis(Redis StackのRedisSearch with Vector Similarity Search)、Elasticsearch(Semantic Search機能)、PostgreSQL(pgvector拡張)なども選択肢として挙げられます。これらのツールは、既存のインフラに統合しやすいというメリットがあります。選定にあたっては、プロジェクトの規模、コスト、運用リソース、スケーラビリティ要件を総合的に評価することが重要です。
データ統合・変換のためのETL/ELTツールとデータレイクの活用
RAGデータ基盤では、多様なデータソースからデータを収集し、前処理を経てベクトルデータベースに格納するデータパイプラインが不可欠です。このパイプライン構築には、ETL/ELTツールとデータレイクが重要な役割を果たします。
データパイプラインのオーケストレーションやデータ処理には、以下のツールが役立ちます。
主要なETL/ELTツール
- Apache Airflow / Prefect / Dagster: データパイプラインのワークフローをオーケストレーションするためのツールです。複雑な依存関係を持つタスクのスケジューリング、監視、管理を効率的に行えます。Pythonでコードベースのワークフローを定義できるため、柔軟なデータ処理ロジックを実装できます。
- Apache Spark: 大規模なデータ処理と分析に特化した分散処理フレームワークです。データのクリーニング、変換、集計など、前処理の多くのステップで利用できます。特に、非構造化テキストデータの解析やエンベディングのバッチ処理において強力です。
- dbt (data build tool): データウェアハウス/レイクハウス内のデータ変換に特化したツールです。SQLを主体とし、テスト、ドキュメント生成、バージョン管理機能を提供し、データ変換プロセスの堅牢性と管理性を高めます。
- クラウドETLサービス: AWS Glue, Azure Data Factory, Google Cloud Dataflowなどのマネージドサービスは、インフラ管理の手間を省き、スケーラブルなデータ統合・変換パイプラインを構築できます。
RAGのデータソースを効率的に管理するためには、データレイクやデータレイクハウスも有効です。
データレイクとデータレイクハウスの活用
- データレイク: 構造化、半構造化、非構造化データを問わず、あらゆる形式のデータを元の形で大量に保存できるストレージリポジトリです。S3 (AWS), Azure Data Lake Storage, Google Cloud Storageなどが代表的です。RAGのデータソースとして、多様な生データを一元的に管理する基盤となります。
- データレイクハウス: データレイクの柔軟性とデータウェアハウスの構造化された管理機能を融合したアーキテクチャです。Delta Lake, Apache Iceberg, Apache Hudiなどのオープンソースフォーマットがこれを実現し、データ品質、ガバナンス、パフォーマンスを向上させます。RAGのデータ前処理後のクリーンなデータや、特定のスキーマを持つデータを効率的に格納・管理するのに適しています。
これらのツールとアーキテクチャを組み合わせることで、データの取り込みからベクトル化、ベクトルデータベースへの格納までの一連のプロセスを自動化し、データの鮮度と品質を維持できる堅牢なデータパイプラインを構築することが可能になります。
検索エンジンの最適化:既存インフラとの連携とパフォーマンス向上
RAGシステムにおける検索は、多くの場合ベクトル検索が中心となりますが、既存の全文検索エンジンとの連携や、その最適化も重要な考慮点です。特に、メタデータフィルタリングや特定のキーワード検索のニーズがある場合、これらを組み合わせることで検索精度をさらに高めることができます。
既存の検索エンジンと連携することで、検索機能の強化が期待できます。
既存検索エンジンとの連携
- Elasticsearch / OpenSearch: これらの全文検索エンジンは、強力なインデックス機能と高速なキーワード検索、豊富なクエリ機能を提供します。RAGにおいては、ベクトル検索で上位K件のチャンクを取得した後、さらにキーワードやメタデータでフィルタリングを行う「ハイブリッド検索」のアプローチで利用できます。
- また、Elasticsearchの8.x以降では、ベクトル検索機能(k-NN検索)も統合されており、単一のプラットフォームで両方の検索を実現できる可能性もあります。
RAGのセマンティック検索機能を深掘りし、その性能を最大限に引き出すための最適化も重要です。
セマンティック検索の深化とパフォーマンス向上
- セマンティック検索の深化: RAGのベクトル検索は、キーワードマッチングだけでなく、質問とドキュメントの意味的な類似性を捉える「セマンティック検索」を実現します。これにより、ユーザーは自然言語で意図を伝えるだけで、関連性の高い情報を取得できます。
- エンベディングモデルの選択とチューニング: エンベディングモデルの選択とチューニングがセマンティック検索の精度を左右します。ドメイン特化のエンベディングモデルや、より高性能なモデル(例: BERT, RoBERTaベースのモデル、Sentence-BERTなど)を活用することで、検索結果の質を高められます。
- 検索パフォーマンスの最適化:
- インデックス戦略: ベクトルデータベースのインデックス設定(例: HNSWパラメータ)を、検索速度とメモリ使用量のトレードオフを考慮して最適化します。
- キャッシング: 頻繁にアクセスされる検索結果やエンベディングをキャッシュすることで、応答時間を短縮します。
- 並列処理: 複数の検索リクエストを並列で処理できるアーキテクチャを設計し、高負荷時でも安定したパフォーマンスを維持します。
- 分散アーキテクチャ: 大規模なデータセットの場合、ベクトルデータベースのシャーディングやレプリケーションを適切に設計し、分散処理によるスケーラビリティを確保します。
これらの技術スタックの適切な選定と最適化により、RAGデータ基盤は、単に情報を検索するだけでなく、ユーザーの意図を正確に理解し、最も関連性の高い情報を高速に提供できる強力なシステムへと進化します。
RAG導入における課題と解決策:現場で直面するリアルな問題
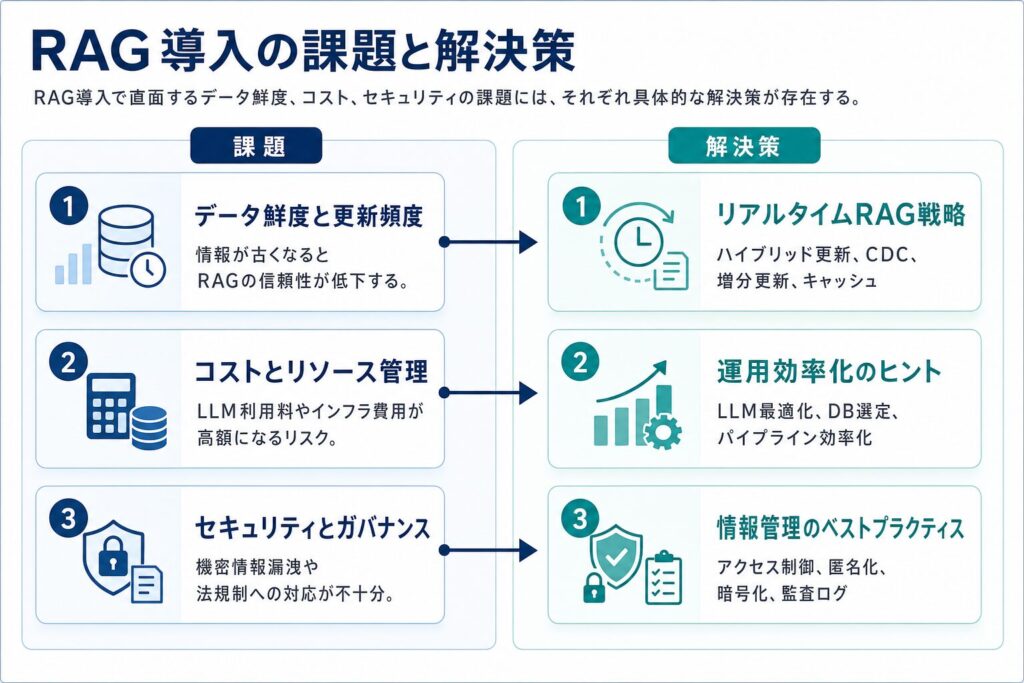
RAGの導入は多くのメリットをもたらしますが、実際のプロジェクトでは様々な課題に直面します。技術担当者として、これらの課題を事前に理解し、適切な解決策を講じることが成功への鍵です。
データ鮮度と更新頻度:リアルタイムRAGを実現するための戦略
RAGシステムの応答品質は、参照するデータの鮮度に大きく依存します。特に、頻繁に情報が更新される業界や業務においては、データの鮮度維持が重要な課題となります。
課題:
- 情報が古くなると、RAGが誤った情報に基づいて回答を生成するリスクが高まります。
- データ更新の遅延は、リアルタイム性が求められる業務でのRAG活用を妨げます。
- 大量のデータを頻繁に更新する場合、データパイプラインやベクトルデータベースへの負荷が大きくなります。
解決策:
- ハイブリッドデータ更新戦略:データの特性に応じ、バッチ処理とストリーミング処理を使い分けることで、効率的に鮮度を維持します。
- バッチ更新: 比較的更新頻度の低いデータ(例: 年次報告書、製品マニュアル)は、夜間バッチなどで定期的に一括更新します。
- ストリーミング更新: 最新性が求められるデータ(例: ニュース記事、チャットログ、顧客の問い合わせ履歴)は、Apache KafkaやAmazon Kinesisなどのメッセージキューを利用してリアルタイムに近い形で取り込み、ベクトルデータベースを増分更新します。
- 変更データキャプチャ(CDC)の導入:データベースの変更をリアルタイムで検出し、効率的なデータ更新を行う仕組みです。
- データベースの変更ログをリアルタイムで捕捉し、変更があったレコードのみをデータパイプラインに流すことで、効率的な更新を実現します。これにより、不必要な全量スキャンや再インデックス作成を避けることができます。
- ベクトルデータベースの増分更新機能の活用:既存のインデックスに対して、必要な更新のみを適用することで処理負荷を軽減します。
- 多くのベクトルデータベースは、既存のインデックスに対して新たなベクトルを追加・更新・削除する機能を持っています。これを活用し、変更されたチャンクのみをターゲットに更新処理を行います。
- キャッシュ戦略の最適化:頻繁にアクセスされるデータを一時的に保存し、応答速度を向上させつつ鮮度を管理する手法です。
- 頻繁にアクセスされるが更新頻度が低いデータは、エッジキャッシュやRedisなどのインメモリデータベースでキャッシュし、RAGの応答速度を向上させます。ただし、キャッシュの有効期限や無効化ポリシーを適切に設定し、データ鮮度とのバランスを取る必要があります。
コストとリソース管理:最適なインフラ投資と運用効率化のヒント
RAGシステムの運用には、LLMのAPI利用料、ベクトルデータベースのストレージ・検索費用、データパイプラインの計算リソースなど、様々なコストが発生します。これらのコストを最適化し、効率的なリソース管理を行うことは、プロジェクトの持続可能性に不可欠です。
課題:
- LLMのAPI利用料が想定以上に高額になるケースがあります。
- ベクトルデータベースのインスタンスタイプやストレージ容量の選定を誤ると、オーバースペックによる無駄な出費や、逆にパフォーマンス不足に陥る可能性があります。
- データパイプラインの処理が非効率だと、計算リソースの消費が増大します。
解決策:
- LLM利用の最適化:LLMの利用方法を工夫し、不要なコストを削減する戦略です。
- プロンプトエンジニアリングの改善: LLMに与えるプロンプトを最適化し、不必要なトークン消費を抑えます。
- モデルサイズの選択: 全てのタスクに高性能なモデルを使うのではなく、特定のタスクには軽量なモデルを使い分けることでコストを削減します。
- キャッシュとリトライメカニズム: 同一の質問に対するLLMの回答をキャッシュしたり、APIエラー時にリトライ処理を導入することで、無駄な呼び出しを減らします。
- オープンソースLLMの検討: 特定のドメインやタスクにおいては、オープンソースのLLMをファインチューニングして利用することで、API利用料をゼロにできます。
- ベクトルデータベースの最適化:利用状況に応じた適切なリソース選定と運用の工夫で、コスト効率を高めます。
- 適切なインスタンス選定: ベクトルデータベースのマネージドサービスを利用する場合、データ量とクエリ頻度に基づいて最適なインスタンスタイプとストレージ容量を選択します。
- オートスケーリングの活用: アクセス負荷に応じてリソースを自動的に調整するオートスケーリング機能を活用し、必要な時に必要なだけリソースを確保します。
- オープンソースのセルフホスト検討: 運用リソースがある程度確保できる場合、MilvusやQdrantのようなオープンソースのベクトルデータベースをセルフホストすることで、クラウドサービスよりもコストを抑えられる可能性があります。
- データパイプラインの効率化:処理プロセスの最適化により、計算リソースの消費を抑えます。
- 分散処理の活用: Apache Sparkのような分散処理フレームワークを活用し、大規模なデータ処理を効率的に行います。
- クラウドサービスの最適な利用: AWS GlueやAzure Data FactoryなどのマネージドETLサービスは、サーバーレスで必要な時にだけ課金されるため、リソースの無駄を省けます。
- 処理頻度の見直し: データの重要度や鮮度要件に応じて、データ収集や前処理の頻度を最適化します。
継続的なコスト監視とリソース使用状況の分析を通じて、常に最適なインフラ投資と運用効率化を図ることが重要です。
セキュリティとガバナンス:RAGシステムにおける情報管理のベストプラクティス
RAGシステムは、企業の機密情報や個人情報を含む多様なデータを扱います。そのため、セキュリティとデータガバナンスは、導入成功の最も重要な要素の一つです。
課題:
- 機密情報がLLMに誤って流出するリスクがあります。
- データのアクセス制御が不十分だと、不正アクセスや情報漏洩に繋がります。
- 個人情報保護規制(GDPR、CCPAなど)への対応が不十分だと、法的リスクが発生します。
- RAGが生成した回答の正確性や妥当性を保証する仕組みが求められます。
解決策:
- 厳格なアクセス制御(RBAC):ユーザーや役割に基づいてデータへのアクセス権限を細かく設定し、情報漏洩リスクを最小限に抑えます。
- ベクトルデータベースやデータソースへのアクセス権限を、ユーザーや役割に基づいて細かく設定します。必要な情報のみにアクセスできるようにすることで、情報漏洩のリスクを最小限に抑えます。
- LLMへのAPIアクセスも、認証・認可を厳格に管理します。
- データ匿名化・仮名化と暗号化:機密情報や個人情報を保護するための基本的な対策です。
- 個人情報や機密情報を含むデータは、RAGシステムに取り込む前に匿名化または仮名化処理を施します。
- データは保存時(Encryption at Rest)と転送時(Encryption in Transit)の両方で強固な暗号化を適用します。
- LLMへのプロンプトに個人情報や機密情報を含まないよう、サニタイズ処理を実装します。
- データガバナンスポリシーの確立:RAGで利用するデータのライフサイクル全体にわたる明確なルールと基準を設けます。
- RAGで利用するデータのライフサイクル(収集、保存、利用、アーカイブ、削除)に関するポリシーを明確に定義します。
- データ品質、データセキュリティ、プライバシー保護に関する社内基準を策定し、遵守を徹底します。
- 定期的なセキュリティ監査とコンプライアンスレビューを実施します。
- 監査ログとトレーサビリティ:RAGシステムでの全ての操作を記録し、問題発生時の原因究明やコンプライアンス対応に活用します。
- RAGシステムへのアクセス、データ検索、LLMによる回答生成など、全ての操作を詳細なログとして記録します。
- これらのログを分析することで、不正アクセスの検知、問題発生時の原因究明、および監査証跡としての利用を可能にします。
- LLMが参照した情報源(ドキュメント、チャンク)を回答とともに提示する機能を実装し、回答のトレーサビリティを確保します。
- 人間によるレビューとフィードバックループ:RAGの回答品質を継続的に改善し、セキュリティを強化するための人的プロセスです。
- 特に重要性の高いRAGの回答については、人間によるレビュープロセスを導入します。
- ユーザーからのフィードバックを収集し、RAGのパフォーマンス改善やデータ基盤のセキュリティ強化に役立てるフィードバックループを構築します。
これらの対策を講じることで、RAGシステムは企業のビジネスを加速させる強力なツールとなりつつも、情報セキュリティとデータガバナンスのリスクを適切に管理できる基盤となります。
まとめ:あなたのRAGプロジェクトを成功に導くために
RAG(Retrieval-Augmented Generation)は、LLMの可能性を飛躍的に広げ、企業固有の知識を活用した高精度なAIアプリケーションを実現する強力な技術です。しかし、その導入の成否は、強固で最適化された「データ基盤」の構築にかかっています。本記事を通じて、技術担当者の皆様がRAGデータ基盤設計の全体像と、その実践的なアプローチを深くご理解いただけたなら幸いです。
今すぐ始めるRAGデータ基盤構築:次のアクションプラン
RAG導入への道のりは決して平坦ではありませんが、適切な計画と段階的な実行によって、そのハードルを越えることができます。以下に、皆様のRAGプロジェクトを成功に導くための具体的なアクションプランを提案します。
RAGデータ基盤構築の次のアクションプラン
- RAGのユースケースを明確化する: まずは、解決したいビジネス課題と、RAGで実現したい具体的なユースケースを特定しましょう。MVP(Minimum Viable Product)としてスモールスタートできる範囲で設定することが重要です。
- データ資産の棚卸しと品質評価: RAGの基盤となる既存のデータソースを洗い出し、その品質、鮮度、関連性、アクセス性、セキュリティ要件を詳細に評価してください。
- データ前処理戦略の立案: チャンキング手法、エンベディングモデルの選定、メタデータ付与の要件など、RAGに最適なデータ前処理の戦略を具体的に検討します。
- ベクトルデータベースの選定と検証: プロジェクトの要件(スケーラビリティ、パフォーマンス、コスト、運用負荷)に基づき、最適なベクトルデータベースを選定し、PoC(概念実証)を通じて性能を検証します。
- データパイプラインの設計(ETL/ELT): データ収集からベクトル化、ベクトルデータベースへの格納までの一連のプロセスを自動化するデータパイプラインを設計し、運用監視体制も視野に入れてください。
- セキュリティとガバナンス計画の策定: アクセス制御、データ匿名化、暗号化、監査ログなど、RAGシステム全体におけるセキュリティとデータガバナンスに関する明確な計画を策定し、早期に実装を開始します。
これらのアクションプランを一つずつ着実に実行することで、皆様のRAGプロジェクトは堅牢なデータ基盤の上に立ち、着実に成果を上げていくでしょう。
RAGが拓くビジネスの未来:技術担当者へのメッセージ
RAGは単なるAI技術の一つに留まらず、企業が持つ膨大なデータ資産の価値を最大限に引き出し、新たなビジネス価値を創造するための強力な触媒です。これにより、顧客体験の向上、従業員の生産性向上、そしてより迅速かつ正確な意思決定が可能になります。
技術担当者の皆様は、このRAGという革新的な技術の最前線に立ち、その実現を支える重要な役割を担っています。データ基盤の設計と構築は、RAGプロジェクトの心臓部であり、皆様の専門知識と実践的なスキルが、ビジネスの未来を大きく左右します。
挑戦は伴いますが、RAGがもたらす可能性は計り知れません。最新の技術動向を常にキャッチアップし、既存のシステムとの連携を模索しながら、ビジネスニーズに合致した最適なRAGデータ基盤を構築してください。皆様の技術力が、企業の競争力を高め、新たなイノベーションを生み出す原動力となることを心から期待しております。このエキサイティングな旅路を、ぜひ成功へと導いてください。